BibleTrans was originally designed to run on a relatively slow computer
with not much memory, so the data structures were designed with frugality
in mind. This necessitated substantial up-front preparation, over and above
what was already required to get the original source documents into a form
that could be easily used. The program to do all this preparation is unimaginatively
called "DocPrep". The process has become so complicated that I
already have begun to forget what needs to be done, so this document explains
it all -- or rather it will when it is finished. There are also a number
of one-off hacks in it that need never be repeated, so the explanation
is a little sparse in those areas.
I later added to DocPrep the ability to examine the binary resource data files.
There are several scenarios when this program is called into use, so each scenario is described as to its purpose and how to effect the build for that situation. Later, (at the end) I hope to give more details on what each module does.
The most common reason (now) for running DocPrep is looking inside binary resource files.
The next most common reason is to rebuild the database after making a documentation change.
I found numerous typo errors in the source documents I got from various providers, so these individual steps (initially) have their own buttons to rerun that part (and subsequent steps) after fixing the errors. That happens less often now, so I have a "Do All" button that should do a complete rebuild from start to finish. Other kinds of partial runs can be scripted.
The processing of particular pieces of data may be spread over several modules but best understood together. From time to time I expect to add to the data flow section of this document.
There are a zillion source and intermediate files that DocPrep
uses, partly so long runs that get aborted for whatever reason can be restarted
with intermediate data, but also so I can look at that data and try to
figure out why the program crashed or did some unexpected thing with the
data. To keep track of these files, I created yet another text file "FileList"
which gives keyword names and full-path locations for each file. DocPrep
calls System routines to access these files by keyword name, which makes
it easier to re-arrange the folder structure without recompiling the program.
Most notable, of course, is the finished "BT_Docs.BTD". binary
file DocPrep builds, and the "xBTdox" ("DoxSource")
text file containing the handwritten documentation; both are accessed through
their respective keyword names.
There is also an icon where you can (in the Mac; I don't think it works in the PC yet) drop a binary file in the MOS resource format, and it will open a window for viewing its contents. With that window open, you can drop a text file on the same icon, and (if properly formatted) it will replace those resources in that binary file. Choosing "ResViewer" from the "Other" menu opens the defined ("BT_Docs") database file. Holding the menu key down while selecting this menu will ask for a file to open.
Several of the steps were long and time-consuming, so I subdivided them
or added alternative operations driven by the same button, selected by
some combination of modifier keys held down when that button is pressed.
This got confusing, so I added a text script that can run multiple steps
in sequence; it also can restart the most recent step not yet completed.
Real
Soon
Now
I expect to revise which procedures are connected to what buttons and give
the buttons more appropriate names. So in this interim edition of this
document, I won't explain the buttons in detail. Hopefully their names
will suggest what they call up, and also are identified (by name) in the
source code.
The file opens in the resource type index, which lists every resource type in the file, and now many resources there are of that type, and where the resource list for that type starts in the file. Double-clicking one type in the index opens its resource list; double-clicking a resource opens that resource. Some resource types are known to the viewer (and others by a callback in DocPrep) so they are formatted for "Best" viewing, but you can always choose to look at the raw data in hex. The file block where that resource is gets reported in the top corner of the window. Click on it to look at an arbitrary (4K) file block in hex.
With any data showing in the window, you can Edit->Copy the whole window for pasting into a text editor. I use this to do searches and stuff that the viewer does not do for me. The data is copied in the displayed format.
With the window open, you can drop a text file onto the file icon, and
if the file is in a recognizable format, the data is imported into the
binary file. The simplest format is if the first line is blank, and the
second line is a resource type as used by the DocLoader
module: then all resources in the file (up to the single dot) are copied
into the open resource file, possibly replacing existing resources. The
(File->Open) menu should do the same as the drop icon, but I don't think
it's working yet.
VfyX 0 VerifyXML -- find mismatched tags in the new text, writes ".err" file if soYou need to make sure the previous full build had the same checkbox settings as this shorter version. This short build takes some 7-10 hours on my 400MHz PPC Mac (longer if running in background and I'm doing other things), and 2 or 3 hours on my 2GHz PC.
ConvDoc 2=xBTdox -- add the new text to existing partial word lists
ConvDoc 6=MakeDocX -- divide the word lists into resources and convert the data
MakeResFi 12=CopyResFi -- collect all the resource data into one file
Loader 0 -- build the binary file from the resource data
After writing up this section, I added some steps to automatically build
the user index from the frequency-sorted word list. The index is just some
additional document pages added to the end of the "DoxSource"
text file (the previous version is deleted). The word list is constructed
as part of the document conversion, so I added controls to stop after it
did that, then to do the whole thing all over again. This is an option
(caps-lock key engaged) with this short run, but unconditional for the
complete rebuild. Building the index adds an hour or two to the PC time.
VfyXML 0 -- validate the documentation file for properly matched tags (3m)The times shown are for the most recent run on my 400MHz PPC Mac several years ago in the previous version; where measured, PC times on a 2GHz Athlon are now about four times faster. Not including the Merge step (sources not included), the PC time for a full rebuild is just under 14 hours. Clicking the "Do All" button with no modifier keys does this run.
MergeGk 0 -- compare Greek texts to extract PD info, gather words & glosses (14h)
DocGrek 0=xBTdox 4=+NetBible -- gather Greek words from document files (4h)
GrekInfo 0 -- divide the word lists into resources and convert the data (18h+10h+9h)
ConvDoc 0 -- build complete English word lists (52h+25h+6h, +2h for index restart)
MakeResFi 1 -- collect all the resource data into one file (4h)
Loader 0 -- build the binary file from the resource data (1h)
The result of this complete rebuild is the binary database file BibleTrans needs to do what it does. It also needs 13 Tree data files for the complete NT, which it will build with empty trees if it cannot find and open "TreeMatt.BTD" when it starts up. You can import (text) exported tree data, then rename a copy of any of these 13 files (for example, "LoadLuke.BTD" for Luke), which if they are visible in the same folder at rebuild time, they will preload. Instead of opening (text) tree files one by one, you can open a single file containing a list of the tree files in the same folder, and it will batch-load them. I have not yet figured out how to do it on the PC, but "Real Soon Now" you should be able to drop that file onto any open Tree window and have it work.
When preparing tree files for distribution, I try to have each episode
open to show the structure three or four levels deep (but stopping at propositions),
and the root discourse node (episode content) selected so it's ready to
translate. Deeper in the tree, I leave propositions open unless there are
several under a collective coordinating relation or variant, and everything
else closed. That way, when the user first opens up a relation, its proposition
subtree is already open to view, but without adding a lot of unnecessary
clutter. Open nodes are indicated in the text file by two spaces after
the L&N number instead of one; the selected node is indicated by "
! " one space before the left brace of the gloss.
A few one-character codes at the front of the line perform special functions.
Comments marked by a hyphen or space are ignored, and the script ends with
a tilde "~". A question mark line is replaced in the file with the current
time and date. To make it easier to restart after a failed step, the file
is rewritten after each step, with the first line moved to the end.
Greek Text
English Glosses
L&N Tags
English Text
Pictures
Active Image Items
Icons
Other Resources
With several thousand Greek words in the GNT, it is not practical to contain them all in one resource. I sorted each type of data by frequency, and whatever would fit into one large resource of the most frequent items is collected into a base resource. The rest are subdivided by episode, typically three to five episodes of data fitting in one resource of each type. Thus while formatting the display of one episode (essentially a paragraph, displayed on one page), we need only two of each resource type, the base, and the collection containing this episode's less common items.
When constructing these collections, several considerations must be
kept in mind. A base ILGW or index resource can only link to base
data resources. I had to add extra code to check for that. It is not necessary
for the episode-related resources of different types to share the same
bedfellows. Word spellings occupy more space than index items, so the divisions
come differently, but this only matters at the edge of the base.
The lemmas in the Greek text (derived from the Strong's number in the case of public domain text) are compared first to the known L&N shapes in newLexnHist (which is maintained manually from feedback derived from building database), and then to the lexical entries in the L&N lexicon to add L&N numbers to the Strong's lexical data, in DoStrongLnN (not part of the main build sequence, but can be scripted with the line "GNTPrep 512"). This file is used by Matchem to add L&N tags or candidate tags to the Greek text as it is extracted from the source files. Also, as we get tagging information from whoever is building database, that will include specific tags attached to the text, which is also merged with the Greek by Matchem.
As part of the GrekInfo process of building the Greek word index, phase P8 extracts and frequency-sorts the L&N tag lists, then divides them into reasonable-sized chunks, and phase P12 builds the resource data. All of the Greek word data (other parts prepared by MkGrkWdRes) is merged as index links in the text file (see ILGW description), by GrkTxtRes.
The "L&NS" resources are constructed in text file "ParsRes" after the "Pars" resources. The comments of the index resources serve to locate the appropriate numbers to insert into the Greek text. For example, in episode 376 (John 3:16-21 in file "GNT-John") verse 17 (which is untagged at this time) has the word "God" thus:
qeos /qeos !NSMN!SMY $12.1 $12.22 $12.25 \God ^40106 ~376which we obviously know should be tagged 12.1, but without our exegetical insight, DocPrep also offers 12.22 and 12.25 as candidates. This is word number 40106 in the word list (file "nWordList") thus:
0.101,1899585 0.258 +29,999000,qeos /qeos !NSMN!SMY $12.1$12.15$12.22$12.24$12.25 \70074 ^40106which from the first item 0.101 we know will be found at offset +101 in the base ILGW resource. The second item tells us about the L&N encoding. If it were a single number, that would be the L&N code itself packed into 16 bits, with the number of characters needed to display it. The low half of the first number (hex 01CFC41) is its place in the base "L&NS" index resource #32767 (from "FC" as shifted, +7FC0) at offset +65, which we can also see in the "ParsRes" file:
121635074 -1.65; 0.258 +29,05/$12.1$12.15$12.22$12.24$12.25The active (first) number here (hex 07400102) tells BibleTrans to look in the base list resource at offset +258 for this list of L&N numbers, which is known to be 29 characters long (from the hex 74, as shifted). That entry looks like this:
6145 0.258: $12.1and is terminated by the zero. The only word in this episode not in the base L&NS resources is "darkness" in verse 19:
6159 0.259: $12.15
6166 0.260: $12.22
6168 0.261: $12.24
6169 0.262: $12.25
0
skotos /skotos !NSNA!SNA $14.53 $88.125 \darkness ^49339 ~376which is word 49339 in the word list:
30233.215,1176628 7.362 +18,X00376,skotos /skotos !NSNA!SNA $1.23$14.53$88.125 \70574 ^49339~376 +6and its L&N list is (from the hex 011F434) at offset +52 into "L&NS" index resource #32765:
75505002 -3.52; 7.362 +18,03/$1.23$14.53$88.125~376and the actual list in "L&NS" resource #7 at offset +362:
535 7.362: $1.23This same list of L&N candidates is duplicated elsewhere in separate resources, so that in each case all the data for that episode is restricted to a single additional resource of each type. I guess in this case, since there is only one such list in episode 376, I could have used one of the other copies, but the effort to find singletons like this exceeded the perceived benefit. We're talking 20 bytes of file space for this instance.
7221 7.363: $14.53
45181 7.364: $88.125
0
You can also have pictures consisting of raw pixels, but this code does not embed them. Ordinarily such pictures exceed the resource size limit, so they are broken up into 4K fragments in "PxIm" resources, which the module PixResData builds from 16-bit (hex) image data.
<img height=84 width=440 align=CENTER>
... </img>
This defines the size and placement of an image. If the width is not
specified, it will be calculated from the position and width of the elements
extending farthest to the right. The default alignment (if not specified)
is centered in its own paragraph. Other possible alignments are FULL
(left-justified in its own paragraph), and LEFT or RIGHT
with text-wrap around the other side.
<Memo> ... </Memo>
A brief comment to identify this image in the text file. It has no
effect on the constructed database.
<Color=5,5,5/>
Sets the (red, green,blue) color for the following items. Each color
component can have a value from 0 to 5, for a total of 216 colors in the
MOS
color model.
<LocVH=24,32/>
Sets a (vertical,horizontal) pixel position for the following items,
relative to the top-left corner of the image.
<LineTo=80,48/>
Draws a line in the current color from the current position to the
specified (vertical,horizontal) pixel position, then makes that position
current. Connected lines may be drawn by a sequence of LineTos
without additional LocVHs between them.
<Rect=40,56/>
Draws a rectangle filled with the current color, with its top-left
corner in the current position, and the specified height and width in pixels.
Consecutive Rects without intervening LocVHs
will share the same top-left corner.
<Text> ... </Text>
Draws the contained text in the current color with its baseline beginning
in the current location, and makes the end of the text current. Any of
the eight intrinsic fonts may be specified as the tag for text elements.
The text should not exceed 63 characters in length.
<Icon=Dot/>
Draws the named or numbered icon with its top-left corner in the current
position. The icon may be one of those defined within the MOS
System, or it must be installed by the program by extending classIconFontFetch.
Drawing an icon may change the current color to whatever was last drawn
in the icon, so you must reset it if you are going to do further drawing
that uses it.
The following items are used to build images of Tree fragments:
<Tabs=0,128,256,.../>
This sets the pixel positions of columns of Tree nodes, if other than
the defaults.
<ColTops=4,20,.../>
This sets the vertical positions of the top icon in each column, if
other than the defaults.
<Node ID=1 Icon=15 col=1>
... </Node>
Each node in this tree is defined by a Node element. The nodes must
be arranged top to bottom, left to right, and numbered sequentially; the
same ID is used in the slot specifiers to indicate how
they are to be connected to parent nodes. A negative ID
number puts the hilight box under it. The node icon should be one of the
31 designated tree icons (numbered 0 to 7, +8 if hollow, +16 if contained
"+", but not zero alone). The node will be placed at the current position
of the designated column, either as specified in the ColTops,
or else under the previous node in that column, or else as specified in
the previous slot specifier for this node.
<Slot>0.3: Thing</Slot>
<Slot ID=2>body</Slot>
Slot specifiers can only occur within a node specifier, and designate
the lines of text for that node. Any number of slots may be specified with
no ID (which are just label text like the L&N code
and noun number), followed by actual slots which connect to nodes with
the designated ID. The connecting slots are indented as
in the tree window, with a dot for the connection, whether or not a node
is connected to it. Three negative ID numbers have special
significance: -1 means there is no node connected to this slot;
-2
means the connecting line extends out horizontally to where a vertical
link line connects it to multiple nodes, but not to any particular node;
and -3 is the same as -2, but the next node in that column
is placed there. Therefore, the nodes must be ordered so that the next
node in sequence for the next column to the right after a -3 connector
is in fact the node you want it connected to, and that it won't collide
with previously placed nodes. Slot text that is "#" followed by a number
(noun number) will be rendered in green; if the text is a valid Bible verse,
it will be rendered in purple; everything else is in black, except a line
that begins with an L&N concept number and a colon, that part only
is blue.
<Link=3,8/>
This draws a vertical line connecting the two nodes, which should be
in the same column.
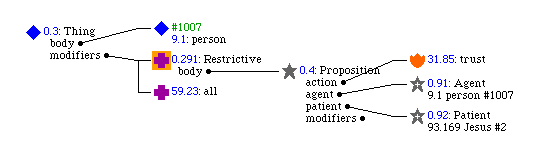
As an example, here is the source text for the example tree 0.291 Restrictive:
<img align=CENTER><Memo>0.291</Memo><ColTops=12,8,8,40/>
<Node ID=1 Icon=2 col=1>
<Slot>0.3: Thing</Slot>
<Slot ID=2>body</Slot>
<Slot ID=3>modifiers</Slot></Node>
<Node ID=2 Icon=2 col=2>
<Slot>#1007</Slot>
<Slot>9.1: person</Slot></Node>
<Node ID=-3 Icon=3 col=2>
<Slot>0.291: Restrictive</Slot>
<Slot ID=-3>body</Slot></Node>
<Node ID=4 Icon=7 col=3>
<Slot>0.4: Proposition</Slot>
<Slot ID=5>action</Slot>
<Slot ID=6>agent</Slot>
<Slot ID=7>patient</Slot>
<Slot ID=-1>modifiers</Slot></Node>
<Node ID=5 Icon=4 col=4>
<Slot>31.85: trust</Slot></Node>
<Node ID=6 Icon=23 col=4>
<Slot>0.91: Agent</Slot>
<Slot>9.1 person #1007</Slot></Node>
<Node ID=7 Icon=23 col=4>
<Slot>0.92: Patient</Slot>
<Slot>93.169 Jesus #2</Slot></Node>
<Node ID=8 Icon=3 col=2>
<Slot>59.23: all</Slot></Node>
<Link=3,8/></img>
1. DocGrek sometime before 4, to build DocGreek
(4h).
ctrl-DocGrk first collects NetBible from xml
2. MergeGk calls Matchem for each MergeBooks
file, -> GNT+Demo/GNT#Demo etc
then (or shft-Merge) calls BuildWords (10h),
-> GNT-Demo/GNT*Demo etc
3. then (or cmd-Merge) calls DoGloss
(3.5h):
DoGlos P1: from WordLst (in GloWords), build Glossy,
-> x/zWordList
DoGlos P2: from Glossy, add list items to Glossy
DoGlos P3: look in sorted Glossy to cut at 2K for
base res
DoGlos P4: in sorted Glossy, replicate low-freq items
by res
DoGlos P5: from Glossy (in GloWords), builds theList
(lists only)
DoGlos P6: from Glossy (still in GloWords), adds singletons
to theList
DoGlos P7: from theList (in GloWords), writes TmpGloss,
builds GlossRes
DoGlos P8: from TmpGloss (in GloWords) and GlossRes
(now in theRefs),
add GloIx to GlossRes, build new GlossList
index in Glossy -> *GlossRes
DoGlos P9: add singletons to GlossList in Glossy ->
*GlossList
4. GrekInfo, shift omits [1-7] (8-13 only 15m, all 18h); needs
lock-MakeRes
GrkWrd P1: read xWordList, build WordLst from lemmas+inflects
GrkWrd P2: read LnNGreek (in WordAry), add to WordLst
GrkWrd P3: read DocGreek (in WordAry), add to WordLst
GrkWrd P4: scan WordLst for base boundary
GrkWrd P5: replicate low-freq WordLst items by res
GrkWrd P6: set res bounds in WordLst
GrkWrd P7: read WordLst (in WordAry), -> *GreekRes/*GreekWds/*AllGreek
GrkWrd P8: xWordList (WordAry), build Pars in Glossy,
LNseqs in Textus
GrkWrd P9: split Pars in Glossy if >1K
GrkWrd P10: from Pars in Glossy, -> *ParsRes
GrkWrd P11: Copy expanded parse codes to file, ->
*ParsRes
GrkWrd P12: clone lo-freq LNseqs in Textus
GrkWrd P13: from LNseqs in Textus, building in xData
adds to *ParsRes
4a. then (or cmd-opt-GrkInfo) calls MkGrkWdRes
(now 8-10h):
MkGrkRes T1: clone low-freq xWordList
items below 4K/3 boundary
MkGrkRes T2: read xWordList, AllGreek,
-> *ILGWres/*nWordList
4b. then (or cmd-ctrl-GrkInfo) calls GrkTxtRes
(now 7-9h) -> *GrkTexRes
4c. then (or cmd-GrkInfo) calls LNtagDox -> LNtargs, adds to *ParsRes
5. ConvDocX; shft-ConvDoc (?14+8/*52h)
reads PartialDox for all but xBTdox
calls BuilDocWrds (all:25h,x:5h) for each source
file, then WrdProc(6h):
WrdPro S1: delete suffixes
WrdPro S2: find base res cut
WrdPro S3: clone off by episode all others
WrdPro S4: mark res bounds
WrdPro S5: make WrdS res -> EngWrds
WrdPro S6: make WrdX res -> EngRes
5b. then MakeDocX (ctl-shift-ConvDoc) for each source -> DocRes
(8h,+N:17h*)
6. MakeResFi reads all files, -> BTdox.txt
6a. (shft-MakeRes) calls PrepTreeGloss, DoMisc, DoShapes
(+lock after GrekInfo: DoShapes/GrekConcept
builds "GreekConc", 4h;
VfyJohn316
reviews also ~DocX#30999 in LixPD)
6b. then (usually only) (cmd-ctl-MakeRes) calls CopyResFi/CopDocSizFi
CopyResFi splits resources #0; CopDocSizFi splits
DocX resources >1K
7. DocLoader, lock includes DumpHex; shift
asks file for DumpHex only
There are numerous cases where different verses gloss the same word
differently. These are accumulated in the gloss list as multiple independent
glosses. DoGloss takes that gloss list, and constructs
numbered sets of glosses, which are then divided up into two groups, the
most common, and then everything else as separated by the episodes where
they are used. These resource numbers are then used to build the Greek
text resource code.
Mostly it's a space, which means the first word is a number to fill the next 32-bit integer of the current resource. The data is stored in the native representation for that hardware, so this step must always be done on a PC for x86 usage, or a (calssic, there being no other kind IMHO) Mac for Mac usage.
If it's a quote (0x22), then all the bytes up to the next quote are text to be stored in sequential bytes in the resource. Text strings always start on an integer boundary, with at least one byte null at the end.
Minus (0x2D) signifies that the following number is a word offset in the current resource, and loading continues from there. This is mostly for readability, because examining the text file was originally the only way to review the data, and is still often more convenient than poking around in a binary file. Accordingly, most of the data comes with explanatory comments generated at the time the file is created.
There may be other specialized data types, but I cannot remember, and they are not used much (if at all). BibleTrans uses most of these same codes, plus a lot of others, for importing and exporting data.
Each resource begins with a "#" line giving its number and size (in integers). Most resources of the same type are grouped together, with the type declared by a tilde "~" (0x7E) line. The file ends with a single period (0x2E) on its own line.
There is an option for dumping out the resource file in hex+ascii as
an undifferentiated text file, but I don't use it very often any more,
now that I have ResViewer.
Rev. 2014 May 7