
by Tom Pittman, PhD
This paper is organized as four sections, each with three main ideas.
We begin with some key Definitions, then proceed
to the Technical Challenges and Linguistic
Challenges encountered, and then conclude with a live demonstration
of our Working Prototype, and progress
report to date.
Before we can discuss what we are doing, we need to make sure we are all speaking the same language. An important part of distinguishing meaning-based machine translation from other efforts at MT is a careful choice of terms and definitions. We hope the first few are obvious, but it doesn't hurt to make them clear before proceeding to the substantive material:
Language -- A finite set of symbols representing things, actions, relations, ideas, concepts, sounds, or anything else, or sometimes even signifying nothing at all; plus a set of rules for arranging those symbols into finite sequences called sentences, and for disallowing some sequences as invalid. Most useful languages define an unbounded set of valid sentences. Natural language (NL) is a language used by humans to communicate with each other, and which (as far as we know) was not purposefully designed for that purpose in historical times. We distinguish NL from artificial languages like C++ or Basic, and for our purposes it is convenient to consider creoles and pidgin languages to be NLs despite their possibly artificial origins.
From this definition it is easily seen that the symbol set of most NLs is itself defined by a language, specifying what are valid words or morphemes in the larger language. We will (somewhat imprecisely) call this the phonological sub-language. The symbol set of the phonological sub-language is the letters and punctuation of the alphabet, or else the phonemes of its spoken version; the written alphabet is typically intended to represent or enumerate those same phonemes. The "sentences" of this sub-language are the valid words and morphemes (that is, the symbol set) of the larger NL.
Most NLs are subdivided into dialects, which are regional or social variations in the symbol set and/or rules that define that language. Strictly by our definition these dialects are separate languages. For this discussion we can safely ignore dialects and assume we are dealing with dialect-free languages.
Meaning -- It is very difficult to give a precise definition of meaning, because it is so arbitrary. In the case of the phonological sub-language of an NL, there is no meaning at all; the entire meaning of the containing NL resides in the lexicon and syntax (and larger discourse structures) of that NL, and none of it in the rules for spelling its words and morphemes. Probably the closest we can come to the true meaning of a sentence in the full NL is either telic or phenomenological, what the speaker (or author) intended to communicate, or else what the fluent hearer or reader of the sentence is likely to have understood from it. This turns out to be fairly close to the (only slightly) precise meaning we assign to a sentence in an artificial language such as C++ or Basic, which often comes out as "whatever the computer does when it correctly processes that language." For mathematical formulas in such languages we can do much better, albeit at the cost of great detail: x+y in Basic means "the sum of the value in variable x added to the value in variable y". Taken to its logical extreme, as some computational mathematicians do, this comes out looking somewhat like Wierzbicka's universal semantic primitives. That is a deep and dark rabbit hole, which we shall gingerly tiptoe around by sticking to our imprecise phenomenological waffle.
An imprecise definition of the term "meaning" might look bad in a paper with "Meaning-Based" in the title, except for the company we keep: Mildred Larson did not even attempt a definition in her book. We hope to be more careful with the other definitions, so that this imprecision does not encroach on the other terms and thus interfere with our thesis.
Translation -- A sentence or sequence of sentences r in language R is said to be a translation of some sentence or sentences s in language S, if r has the same (or approximately the same) meaning in R as s has in S. Approximation is often the best we can do when there is no one-to-one equivalence between the symbol sets of R and S, as is usually the case with NLs. Even with artificial languages used in programming computers, approximation may be necessary. Consider the expression "10.0/3" in C++, whose meaning (value) cannot be written as a precise decimal number, except by some subterfuge like elipsis: "3.333..." I have acquired some notoriety for the language TinyBasic; it only does integers, so the closest we can come to a translation is "10/3", which has the value (in TinyBasic) of exactly 3. This is an imprecise translation, but it is often adequate for the purpose at hand. For example, pi (3.14159...) comes out to be exactly 3 based on the round numbers reported in 1 Kings 7:23. It is an approximation in that context which is good enough for almost every reader except a few modern mathematical pedants.
On the other hand, sentence r' is not a translation of s if a fluent reader of the sentence s understands a substantially different message than the fluent reader of r' does. For example, an English-speaking shopper can go into any furniture store and pointing to a table ask "How much?" and be understood to be enquiring about the price of that table. But if he goes into a furniture store in South America and substitutes from his dictionary the apparently equivalent Spanish words "como" for "how" and "mucho" for "much" from his dictionary, the clerk will wonder why he is describing his eating habits, or perhaps offer him a larger table, because "como mucho" means "I eat a lot" in Spanish. The correct translation of his intended question is "Cuanto cuesta?"
From this definition of translation it follows directly that all correct translation is meaning-based. If the reader of the putative translated text does not understand it in approximately the same way the native reader of the source text would have understood it, then it is not a translation at all. Consistent-change word substitution is not translation unless the words and syntax are in fact equivalent.
Computer -- An electronic device comprising one or more input devices such as a keyboard or mouse, one or more output devices such as a printer or display screen, a place such as a disk drive to store intermediate data, and decision-making circuits enabling data accepted from the input device(s) to be transformed in some data-dependent way and then presented on one of the output device(s). Most modern computers include as part of the decision circuitry, additional data called software, which is a set of detailed instructions for the decisions to be made. For our purposes here we do not distinguish between the software and the computer it controls. Programming a computer means specifying the sequence of decisions the computer will use to perform its task.
Machine Translation -- The process of using a computer to do translation, that is, to accept as input sentences s in language S, and to display as output corresponding sentences r in language R, such that r is a translation of s. Machine translation of artificial languages like C++ and Basic into other, even more artificial languages (like the binary internal code of computers) is an established fact; we do it regularly and we do it well. MT applied to NLs has never been really successful, despite 60 years of intense research effort.
If we succeed at what we are doing, it will be because we are not attempting the latter exceedingly difficult job (MT applied to NLs), but rather something more closely resembling the former (at least inside the computer).
Now for the substantive definitions, in three contrasting pairs:
Syntax -- The rules of a language, which control what are valid sentences in that language without regard to the meaning of the symbols or the resulting meaning of the sentences. English language syntax forbids putting a transitive verb at the end of its sentence (Pie John loves*), but it says nothing about what are often called collocation issues, such as attributing an attitude like love to an inanimate object like pie (Pie loves* John). We distinguish syntax from
Semantics -- Those parts of translation that are concerned with meaning, and not with correct form. The lexicon of a language (its symbol set of words and morphemes) generally assigns one or more meanings to each lexical entry. The spelling of the lexical entry is syntactic, and the assigned meaning is semantic. Similarly, the syntactic rules for sentence formation, while not about meaning in themselves, also carry meaning: The noun phrase at the front of a normal-form English sentence is the subject. It is required to be in the nominative case (which is only distinguishable when it is a pronoun), and that is syntax; it is also the agent of the verb's action, which is semantics. If plural, the "-s" suffix is syntax; the significance we attach to that suffix (that is, that it refers to more than one person or thing) is semantics.
Syntax carries semantics in the sense that there is no way to infer the meaning of the sentence apart from the lexical meanings of the words and morphemes and the syntactic transformations applied to them. Conversely, the semantics drives the syntax. Given the semantic idea that a person named John has a preference for a food item called pie, and not the other way around, in English a reference to the person will occur before the verb, and the object of his preference will occur after it. Semantic considerations may select whether to refer to this person as "John" or "he" or "my brother," and whether to choose "like" or "love" or "prefer" as the verb, but syntax puts the person before the verb and appends "s" after the verb.
All translation proceeds in two phases:
Analysis -- The first phase of translation, in which the translator (or in the case of MT, the computer) analyzes the syntactic form of the source text and extracts from it the meaning of the sentence(s) to be translated. This is exceedingly difficult, and not even native speakers of the language get the analysis correct every time. This analysis failure is called misunderstanding when people do it in natural communication contexts. The fact that computers do not understand has severly limited MT, and most modern research in MT is attempting to correct that deficiency.
Synthesis -- The composition in the receptor language of sentences carrying the same meaning extracted by source text analysis. We succeed at our version of MT because we know how to do the synthesis mechanically, but leave the source text analysis to be done manually. We will say much more about this later.
Finally, we are interested in one particular style of syntax specification or grammar. We note two kinds:
Descriptive -- The emphasis of a descriptive grammar is on describing all of the language features, typically by enumerating them and giving representative examples. By implicit or explicit comparison with other languages, the description can be abbreviated and limited to the distinctives of this language over against the others to which it is compared. The intended user of the grammar seeks to be able to understand utterances (sentences) in that language, typically by applying the rules of the grammar to those sentences to decompose them into elements of meaning.
Generative -- A generative grammar specifies by successive refinement how to construct valid sentences in the language. It may be less complete than a descriptive grammar, if it is deemed unnecessary to generate every possible valid sentence, and it may be less easily understood because the emphasis is prescriptive, not descriptive.
The idea of successive refinement follows from Chomsky's language hierarchy. Although his later work of trying to intuit language universals without actually studying NLs was misguided, Chomsky's mathematical analysis of language types has long served as a powerful tool for understanding and building MT software in the computer science community. Put very simply, a generative context-free grammar is a set of rewrite rules, in each of which a semantic unit like a noun phrase or clause is rewritten in terms of its component syntactic and semantic units, until there is nothing but syntactic elements left; the result is a valid sentence in the language. When the choice of which rule to apply is driven by the semantics of the message being translated, you get high-quality and provably correct (that is, meaning-based) translation. We have been doing this and doing it well for many years.
When we put these definitions together, it becomes clear that we have the technology to do the synthetic phase of MT (to a NL, using a generative grammar), provided that we find some other way to handle the analysis. This important insight seems to have been missed by other people working in MT -- or perhaps it is only in Bible translation that it makes any sense to attempt such a partition of the task. Most translation tasks are receptor-driven, the readers of one language seeking to translate many documents from one or more other languages into their own language. The burden of such translation is on the analysis, which as we observed above is exceedingly difficult. Bible translation, on the other hand, consists of but a single document to be translated into thousands of different languages. We can afford the high cost of doing the analysis (by whatever means, but probably manually), if the synthesis can be automated and done very quickly from a single language-neutral semantic representation of the Biblical text.
The result of this insight is a computer program we call BibleTrans. It facilitates the manual creation of a semantic representation of the Biblical text, stores this intermediate form in a semantic database from which any number of translations into arbitrary NLs can be made. It further provides a way to specify a generative grammar specifying the language into which the Bible is to be translated, and then does the actual translation from the semantic database into that language by applying that grammar.
From our definitions, we can see that if the semantic representation is properly built, and if the grammar for the receiving language is correctly specified, then the result is indeed a meaning-based translation.
In the next two sections we discuss some of the technical and linguistic
challenges we have met and overcome in getting this program functional.
Semantics Representation -- The internal representation of the semantic data is in fact yet another language, with its own symbol set and rules for valid sentence formation. This is an important insight, because it enables us to choose that representation, as well as the translations to it from the Biblical texts and from it to the receptor languages, on the basis of sound computational linguistic theory.
An early exposure to other languages protected me from the fallacy of thinking in terms of word substitution as a means of translation. The internal representation therefore had to be semantic (meaning-based) in order to capture uniquely the meaning of the original texts. The symbol set of this internal language must be based on the meaning of the original texts, not on the words.
To make a uniform and teachable translation mechanism possible, the internal representation also must be hierarchical (tree-structured). This structure constitutes the rules for that internal language, and (except for the consistency checks we added later) the same rules apply uniformly everywhere. Thus the analysis phase of the back-end translations is trivial and easily mechanized. It also has the interesting effect that discourse semantics is essentially free: the structures are already there and no more costly to translate correctly than the word order and collocation issues.
I experimented with different kinds of tree representation and settled on a uniform node representation that encodes a single number representing the semantic concept, with links respectively to lists of sister and daughter subtrees. We had some problems teaching early testers to build semantic trees to our rigid specifications, so a lot of work went into setting up verifiable constraints on the tree shape based on the semantic class of the node and other (less general) criteria. The software now performs these consistency checks on all tree modifications and displays non-conforming tree nodes in a visually distinctive manner.
Syntax Representation -- If deciding on a tree-structured semantic representation was easy, finding a usable and teachable way to represent the receptor language syntax proved to be very difficult.
From the theory behind the Chomsky hierarchy as we teach it in computer science classes, it was clear that Transformational Attribute Grammars (TAGs, the subject of my dissertation research, see Pittman&Peters) could do the necessary synthesis for any natural language, given a carefully crafted and unambiguous semantic database tree. All of our translation samples to date (including three non-European languages) were specified by TAGs. The problem is that TAGs are not easily taught to non-programmer OWLs.
Early prototypes of the software allowed for much more language variability than it now appears is justified by field data. Based on Comrie's Language Universals we have been able to make a number of simplifications without compromising the generality of the software.
The model we are currently working with (which has not yet been fully tested) consists of a set of about 300 yes/no and multiple-choice questions originally inspired by, but now substantially extending, the summary questions in Payne's Describing MorphoSyntax. To this we added about 100 lists and tables encoding the relations between the syntactic elements of an arbitrary language. All of this is driven by a single objective, to specify a single (possibly context-sensitive) output phrase for every semantic concept in the database. Some of the tables directly link the semantic tree concepts to output text; others associate intermediate variables with these concepts, then recombine these variables in user-specified ways to conditionally generate output text based on collocation issues or any other criteria as may be appropriate to the linguistic situation. It is still incredibly complicated for real languages (not surprisingly, since languages themselves are complex), but substantially more understandable than TAGs.
User Interface -- The internal syntactic and semantic representations are not worth much if encoding and editing the data is difficult or unattainable. From the very beginning, the goal was to present the user with a visual direct manipulation interface hopefully resembling the way OWLs are accustomed to visualizing their data. This last hope proved to be elusive, as there does not appear to be any consistent model among linguists for data representation.
Nevertheless, we have developed a fairly intuitive (that is, teachable) graphical representation for the semantic tree data, which allows the user to drag tree nodes around on the screen to build correctly formed semantic trees from the concepts that are directly keyed as much as possible to the original Greek (and eventually Hebrew, but not yet) text, also on-screen. Apart from minor improvements, this representation has been quite stable for more than three years.
This is a tiny fragment of the tree representation of John 3:16:
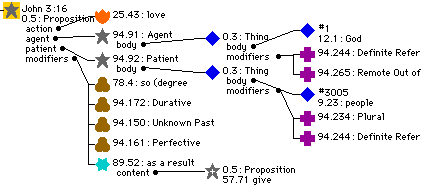
Most of the new syntax model is pretty obvious -- after all, what can you do with tables and lists? The questions we present in the form of checkboxes and radiobuttons.

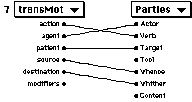
We have two unusual graphical presentations for some of the data. Where the user is concerned with the sequence of elements in a noun phrase or clause, we place these elements on a line where the user can drag them around to get the sequence correct. One of the goals in this is to make typing errors impossible. At each point in the interface, the user supplies the requisite "value-added" data, and the computer provides what it already knows.

A two-dimensional table is the most general way to relate the elements of one list to the elements of another list in an arbitrary way (and we do that), but a more visually compelling presention of the same data when it's not too complex is by drawing connecting lines between elements of the two lists side-by-side on the screen.
Ontology -- The selection of a suitable symbol set for the intermediate semantic tree language, which in MT circles is called its ontology, is like a giant Slough of Despond; in it there be dragons. The fundamental problem is that every language tiles the universe of ideas slightly differently, and the speakers of each language think in terms of their own lexical set of concepts. Even Wierzbicka, when discussing her universal semantic primitives in the context of particular languages, is at pains explain the conceptual mismatches. Every translation must cope with this mismatch when transferring the meaning of the source text into the symbol set of the receptor language, and in the process some nuances of meaning will necessarily be lost, more or less as the two symbol sets are more or less different. In numerical computations we experience loss of precision from round-off error, and an entire field of computer science is devoted to reducing the accumulated loss in accuracy to a single round-off error.
The best of all possible translations similarly experiences at most one "round-off error" in the transfer. Our choice of implementation, using an intermediate semantic tree language, breaks the process into two separate translation steps, each with the potential of introducing its own "round-off errors." The way to minimize the effects of a double numerical round-off is to extend the precision of the intermediate values, minimizing any round-off getting to those values. Wierzbicka's universal semantic primitives are a step in that direction, but with a long way to go.
Unlike numerical computations, we can entirely eliminate the "round-off error" in the first translation by using exactly the same symbol set for our intermediate semantic tree as is used in the original Greek (and eventually, Hebrew) texts. Does this not bring word substitution in the back door? Not at all! We are dealing here with concepts, not words. Our ontology is based on the semantic concepts available to the collective 1st century readers of the original texts, not the particular words used to express those concepts.
Providentially, there exists an excellent lexicon, Louw&Nida, organizing those concepts by semantic domains and tying them to the Greek words. Thus when "God so loved the world," it is not (English) God who does the loving, nor even Greek qeoV (theos), but concept 12.1, which distinguishes this as the Creator God of the universe from the pagan deities 12.22. Similarly, the object of His love is not the modern blue sphere in space, the 3rd planet of a particular solar system, nor the Greek kosmoV, which could in some contexts refer to the entire created universe, and in others the adornment (cosmetics) that people wear, but rather a metaphorical extension of the root Greek concept and captured in L&N 9.23, "people of the world." Where a single Greek word resolves into two or more senses in different contexts, Louw&Nida assigned it different concept numbers. Where several words may be used synonymously (perhaps by different authors), they are assigned the same concept number. The numbers in this lexicon are truly semantic concepts, exactly what we need for our ontology to make this a meaning-based translation.
Unfortunately, Mssrs Louw&Nida have produced a lexicon, that is, all of their concepts are lexical and manifest in the meaning of the Greek words; there is nothing in there for discourse semantics, focus, mood, tense, voice, case, number, participial usage, and all those other sublteties that we get from word order, inflection, forms and genre. These too are part of the meaning, and need to be reflected in the meaning-based ontology. To address these issues, Todd Allman, Steve Beale, and I (ABP) met in 1999 and hammered out a set of extensions to Louw&Nida covering essentially all of these non-lexical concepts. The result is Providentially a very good ontology that accurately captures the entire meaning of the Greek text with little or no transfer ("round-off") errors.
Of this extended L&N ontology a very reasonable question might now be asked: What about "round-off errors" in the back end? Louw&Nida constructed their lexicon with third-world translation in mind, and many of the definition texts include hints on how to transfer these concepts into languages that lack matching concepts. Similarly, the ABP extensions include discourse concepts derived from the Semantic Structure Analysis (SSA) ontology, which was designed for the same purpose, and our own inflectional concepts are rather more detailed than those carried by the Greek, rather like using an extended precision number for intermediate numerical calculations. There will necessarily still be mismatches in the back-end translations, but hopefully we have minimized their impact on the translation effort.
Rhetorical Devices and Exegetical Differences -- It might seem strange to treat both rhetorical devices and exegetical differences under the same heading, but it turns out that both kinds of potential problem are readily solved with a single mechanism, redundancy. The semantic representation has concepts in its ontology to express alternative encodings of the same source text. In one class of alternatives, there are legitimate exegetical differences of opinion as to the correct interpretation of the Greek text (and more so in the case of Hebrew), and we encode all credible alternatives and mark them as such. Thus the burden of making that final decision rests firmly where it always has, in the hands of the linguist or translation committee responsible for the final product. We provide the choices and a mechanism for choosing among the options.
There are two kinds of rhetorical devices that deserve our attention. The most obvious kind are the metaphors, litotes, irony, and other figures of speech where the meaning of the text differs significantly from the surface Greek. We encode both the surface form (so marked) and the true semantic meaning. The user can thus choose (on a case-by-case basis, if desired), if the figure of speech makes sense in the receptor language, to use it literally; alternatively, the default encoding captures unambiguously the author's intended meaning in terms of the ontological concepts. A "literalistic" back-end translation thus ends up looking like what some critics call a paraphrase, while a more careful and nuanced translation can paradoxically recapture some of the formal equivalence of the original texts.
The second kind of rhetorical device is much more subtle. The shame we might feel at not handling it adequately is mitigated somewhat by the fact that manual translations mostly fail also. These are the figures of speech, poetry, and alliterations which are intimately tied to specific words of the original language, such as the names of the 12 sons of Israel, the play on Onesimus' name in Philemon, and the literary connection in John 6 between the five artoi (small loaves of bread) Jesus used to feed the crowd and the artoV (bread) that came down from heaven. There does not seem to be any good way to bring these aspects of the meaning across in translation. Puns simply don't translate.
Credible Test Data -- Finally, I could say something about what feels more like a political problem than anything else, a sort of Catch-22. The mathematical theory that underlies the BibleTrans translation engine clearly supports our ability to claim successful meaning-based translation into any NL. The tiny snippets of text we have translated so far into a variety of non-European languages with credible quality supports this claim. The Wycliffe "Vision 2025" initiative suggests (and they openly admit) that they cannot achieve their goal without radical changes in the way translation is done, changes like the use of MT in controlled ways as we are attempting to do. The initial hurdle of encoding the entire Bible into our semantic database is comparable in cost to a new translation of the Bible into a third-world language, but all our test data suggests that we can obtain good quality first-draft translations (not church-ready, but ready for mother-tongue translator clean-up) out the back end in three to six months each. Despite all this (or perhaps, if you like conspiracy theories, because of all this), qualified people seem reluctant to invest a small amount of time and expense to make it happen, and unless we can build a quality database, qualified people will be reluctant to risk very much of their translation schedule trying to use it. I don't have a solution to this problem other than believing that God's time has not yet arrived, or else that God can make a quality product happen without using experts.
We certainly hope nobody is put off by the unfounded fear of being replaced by technology. We cannot do that. All that BibleTrans does is multiply and leverage the linguistic and translation skills of the people already on the job. It automates the repetitive parts of Bible translation to speed up the whole process, but the human analytical skills are still very much a key part of the job.

"I don't have time to look at newfangled toys, I have a battle to fight!"
The translation engine is fully functional and has been stable for three years, as are also the tools for preparing and working with the semantic tree database. The receptor language grammar editor is new and not yet fully functional as of this writing.
Encoding the Semantic Data -- Because BibleTrans does not fully mechanize the source text analysis, we are looking at a massive investment of skilled labor to build the semantic data tree. Experience with a couple dozen verses (in equal parts narrative from a gospel and didactic from a Pauline epistle) leads us to expect experienced exegetes to build about one verse per man-day, including consultant review and trial translations.
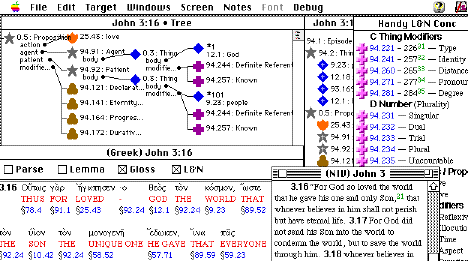
We begin with the UBS Greek text, interlineated with Louw&Nida concepts. Tagging each word with its L&N sense goes reasonably quickly using our semi-automatic tools. To this we add a convenient catalog of ABP extensions, a window containing the tree being constructed, and typically an English translation for reference. These are all integrated in the same software for interoperability.
The software knows which concepts are verbs, which are nouns, adjectives, adverbs, and relations, so it can build a skeletal tree of the appropriate shape as these concepts are dragged into place. The user need only choose the concepts to use and supply (by visual placement) the logical relationships between them. The most labor-intensive part of the process is the correct and detailed exegesis of the text.
Encoding the Language Data -- Human language is incredibly complex, and no amount of computational legerdemain can erase that fact. We have one or two mitigating factors going for us, that we are not attempting to produce church-ready, Shakespeare quality text; instead we expect Mother-Tongue Translators (MTTs) to be trained in smoothing out the rough edges. It is sufficient only that the draft translation be semantically (exegetically) and syntactically correct. The natural reluctance MTTs might have for revising the work of the ex-patriot expert linguist need not apply to the output from a mere machine. Some of their corrections can be fed back into the grammar to produce better drafts over the course of weeks or months, and the rest are best left for final revision manual edits.
Although the largest part of the work of encoding the language grammar is entering lexical data, that should go fairly quickly. This is a generative grammar, so we are interested only in how to realize each L&N concept and ABP extension in the receptor language; we have no interest at all in the different words might exist for mosquito larvae, nor for third cousin by marriage twice removed, as these concepts do not appear in the Biblical text. At the same time we do need to develop appropriate receptor concepts for sacrificial lamb, self-giving love, and other theological concepts -- but the translator must solve these problems in the manual translation also; we have not added to the burden in those cases.
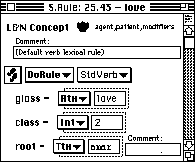
Much more intellectually challenging is the initial effort that must go into encoding the phrase and sentence structure rules of the grammar. This process can be iteratively refined, beginning with a limited number of sentential forms, then adding the more obscure forms after the software begins to produce intelligible text. The simplest and most incomplete initial steps might produce only indicative narrative, beginning with a listing of the components of a noun phrase, then arranging those components on a sequence line. The clause or sentence works the same way. This we then link to the appropriate ABP inflectional concepts in a check-off table.
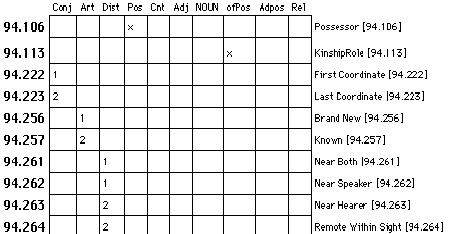
The kinds of sentence structure complexity this will support is severely limited, perhaps good enough for a children's translation, but not up to the quality we expect for adult reading.
A simple example will suffice to demonstrate the problem. There are three slots for helper verbs at the front of the maximally inflected English main verb, with a limited menu of words permitted in each slot. All three slots are independently optional, as in the following examples:
John loves Mary (simple present)The first slot carries modal helpers, the second perfect tense, and the third slot holds continuative helpers. Each filled slot controls the inflection of the next word, not merely the next slot. Thus the first word is always inflected (if possible, most first-slot words are uninflectable) for past and subject agreement. If that first word is in the first slot, the next word (in whatever slot) is in the infinitive form. The second slot is required to be followed by the past participle, and the third slot by the present participle.
John loved Mary (simple past)
John will love Mary (future)
John is loving Mary (present continuous)
John has loved Mary (perfect, with continuing results)
John will have loved Mary (perfect from a future perspective)
John will have been loving Mary (perfect continuous in the future)
Then it gets interesting. For certain classes of questions, the subject, which normally comes before the verb in SVO order, is inverted with the first word of the verb, but it never comes after the last word. If the tense-aspect-mode rules do not provide any helpers, a properly inflected pro-verb "do" is supplied in the first slot. Similarly, in a negated verb the "not" follows the first word of the verb cluster, but never after the last word, requiring again a pro-verb if no helpers otherwise exist.
John did not love Mary (added "do" to simple past)The distinctive feature of these special verb slot rules is that they are based on word count, not the the semantics of the words being considered. So here we have a meaning-based translation engine that all of a sudden must switch gears and look at meaning-free syntax. This particular example is peculiar to English, but other languages have other rules just as obscure and unpredictable as this. Time and space do not permit showing in detail how to do these kinds of things; suffice it to say that the easiest way to deal with the situation without adding ad-hoc English-only hacks was to define sequence variables that can switch generated terms on or off based on contextual information, then replicate the verb cluster on both sides of the subject. The operative word here is variables, which carry contextual information around the semantic tree to make it available at the point and time when the translated text words need to make those decisions. The grammar entry tables give an unbounded opportunity to define these contextual variables and to cross-link them as needed to accomplish any decision-making conditions that affect the generated text.
Did John love Mary?
John will not love Mary (no "do" needed)
Will John love Mary?
John has not loved Mary
Is John loving Mary?
Translation -- After we have the Biblical text encoded as a semantic tree, and after the receptor language grammar has been encoded, or at least after we have done a small part of each, we can begin to translate. I use the word loosely here, because of course it is not a correct translation until the database and grammar are complete and correct, but getting there is often an iterative process.
The translation engine "walks" the semantic tree, first picking up contextual information as it goes, then after it has gathered what it needs, it walks the tree again, generating the output text for each semantic element as it encounters that element. Because the generative grammar specifies what to generate for each semantic node and which subtrees to traverse in which order, the output text comes out in linear order with all collocations in place and correctly inflected. In deference to the preference of OWLs, there is also a separate post-generation pass over the text to apply phonological rules. At the expense of some additional syntactic complexity the translation engine is perfectly capable of effecting these transformations on the fly as the text is generated.
We can also annotate the translated text with gloss words. The top line here glosses the English text with the L&N concept numbers, but this would normally be filled with English glosses to facilitate evaluation of the (non-English) translated text.

An important part of the translated text is a history of which rules
contributed to its generation. This enables the user to examine mistakes
in the generated text in terms of why they occurred, the more easily to
correct the grammar errors. It is an interactive environment. When the
last enquiry is complete and the last mistake corrected, the translation
is finished. The same grammar can be applied to the rest of the text, but
again it is likely that there will be previously undiscovered mistakes
to be corrected.
Is meaning-based machine translation of the Bible possible? Once
you factor in the manual construction of the semantic database, we think
so. Our pilot runs to date are still quite small, but we now have promised
funds to build a complete (four-chapter) epistle, and are actively seeking
partners to help us get there with a quality product. Running a full translation
of that epistle into a variety of receptor languages should then go as
quickly as linguists are willing to commit the time to it. So far, none
of the languages we have encoded has taken more than two weeks for the
basic phrase structure and a modest lexicon. We consider those numbers
realistic in general.
For more information, see the BibleTrans
web site
Tom Pittman
P.O.Box 480
Bolivar, MO 65613
email: TPittman@IttyBittyComputers.com
*Note: Contact information has been updated for this posting, and is current as of 2005 February 7.