BibleTrans Progress Report
What do you do when you have no manager to report
to, nobody who cares what you do or whether you do anything at all? At
the university the department chairman had the responsibility to make sure
the classes were taught. While he may not have cared much what I taught
them (so long as the students didn't fail or revolt), I could always walk
over to another faculty office and discuss what I was doing. Maybe he didn't
care either, but at least he listened without looking obviously bored.
When I sold software to the public, the publisher (or
in the case of shareware, the customers themselves) were always there with
feature requests and bugs to fix.
Now I have no supervisor and no immediate customers. Whom
do I report to, God? OK, God, you got me into this; here's what I have
been doing so far...
Warning to casual lurkers: this page is somewhat
technical, about what I would say to a technical manager, if I had one.
You can probably get the gist of what's going on without understanding
all the technical details, but please feel free to ask questions (see home
page for email). Questions help keep me honest.
I'm keeping a separate log of significant
design decisions.
Date of this report: 2016 December
27. I moved to Oregon. Today I sent letters off to cancel the licenses
used in BibleTrans. God can still do anything He wants, and if He wants
to make BibleTrans happen, and if that includes me, I will jump on it like
there's no tomorrow (and revive the licenses if necessary). Until then,
I have something else to do, something useful enough to attract more people
than just me, something useful enough that somebody is actually willing
to pay me for my efforts. That's better than most of the last 20+ years.
Brief summary of previous progress.
Back to BibleTrans home page
Active Projects
Framework. This is a library of system-like functions that provides
platform independence. I use my MOS application program interface (API),
but implement them in C directly calling the Win32 system calls for maximum
flexibility. At 4400 lines of C (+6300 lines of T2, as of 2013 March, not
counting 16,000 lines of code shared with the MacOS version of the Framework),
it's somewhat smaller than the whole MOS operating system (15,000 lines
of T2, not counting 5000 lines in the virtual machine). The framework used
to work, so it shouldn't change much. Done and working.
Data Resource Access. On the Mac I could use their "Resource
Manager" to store little independent pieces of my data. I don't think the
inferior platforms have such a thing, so I have to write my own. Windows
has "resources" but it doesn't look like you can update them at runtime.
Done and working.
Tree Editor. This enables a skilled exegete to build the semantic
database by dragging icons representing semantic concepts into a structured
representation of the Greek sentences and paragraphs (see
example). The smarter we make this part of the program, the faster
we can build semantic database and enforce the consistency
necessary to make writing translation grammars relatively easy. Done and
working.
Grammar Editor. This enables a linguist to build a grammar defining
how to form words and build sentences in the target language (see
example). I have been using this version, and it seems to work adequately.
There are places where as a programmer I can think of easier ways to do
something, but at least most everything is possible without looking
like a programming language. Done and working.
Translation Engine. This is the part that actually does the translation.
For me it's the easiest part, because it is so similar to a compiler, of
which I have written many. Done and working.
Output Viewer. When the translation is all done, all you want
is text (possibly in a strange writing system), but there will be many
mistakes in the translation rules to correct before the text is usable.
For this you need to be able to see what rules were applied in producing
this text, and then follow them back to see where the mistakes were made
(see example). Done and working.
Document Viewer. A program this complex needs a lot of on-line
help dynamically linked to the program parts for easy access. This works
something like an extra-smart web browser. Done and working.
When I started, I got everything off the Translator's Workplace CD,
and wrote these big hairy HyperCard programs to put it together in a usable
form. Today I'm trying to build as much as possible from public domain
sources, so I wrote these big hairy HyperCard programs all over again.
At least I can run HyperCard; Apple no longer supports it nor the (MacOS)
system it runs on. (2006 June) HyperCard is out of the loop. Programming
T2, while faster than C/C++, is still a lot harder than throwing things
together in HyperCard. sigh Done and working (2008).
NotePad. I found it helpful to be able to jot down notes to myself
as I was working. Even better if we can hyper-link these notes to the data
to which they refer. For the first cut I am depending on WordPad (included
in the WinXP system).
Programmers are an optimistic lot (or maybe it's
just hubris ;-) We tend to think we can do anything, and sometimes that
is correct in specific instances. Software is the new Tower of Babel, concerning
which God said "Nothing they plan to do will be impossible for them." It's
true. Lest I get too cocky, I needed to set a time bound on the tool-building:
This
year (2004) only. The original deadline I set for myself in May was
that if by Christmas I didn't have the complete MOS, editor, and (hopefully)
T2 compiler running and usable in IBSM, then I give up and just write BibleTrans
in (blech) C. Because of the unplanned time I spent on a (paying) Windows
program, I adjusted the schedule somewhat: I wanted to double-click icons
in a Finder-like window to run the programs, on the PC by the end
of January. The idea was if by Easter I'm still not
making forward progress using these tools to build BibleTrans -- in other
words, if I'm still spending more time fixing tool bugs than working
on BibleTrans code, then the tools aren't going to make it and I need to
cut my losses and get on with the real project. I met the January deadline
then
discovered how much more there was before it really became usable. At the
end of February I pulled the MOS plug. It isn't going to happen -- at least
not in the BibleTrans critical path.
Please, God, I know humility is a virtue, and all the other programmers
are stuck with abominable C/C++ tools as are commercially available, but
I think using good tools will so much improve my progress and my positive
attitude that it will fully repay the 7-month investment in building them,
so that the final project will finish sooner and be more reliable than
if I just spent the whole time fighting -- er, ah, "using" the commercial
products. Hey, already (in 2004) it's going faster than things did in HyperTalk!
Better tools really do make a big difference.
By 2005 March I was thinking that I could cobble together a translator
in HyperCard to generate C from the Turk/2, then write (and test) BibleTrans
in Turk2 before converting it to C for deployment. I'm not wasting a lot
of time making the rest of MOS work, and I still do a little debugging
on the PC, but debugging sure is easier on my own tools. In 2006 I switched
over to debugging on the PC, rather than spend a lot of time keeping the
Mac version of the framework up to par. The Microsoft compiler and debugger
have given me a lot of trouble, but arguably less than keeping my own tools
up to date.
After uploading the most recent downloadable version (2010), I decided
to revise the sources to be more OOPS-like, and to
get it working on the MacOS again. The revision is more or less complete,
except that it's full of bugs. Now I have bugs in the Win32 framework to
fix too. Hopefully by the end of 2013. Actual completion: 2014. It works
the same on MacOS and WinXP, from essentially the same source code, all
uploaded. The tables need to be bigger, but it works today (2014).
Time Log
For more 2004 details see
the MOS log.
2004 May 21 -- Formally started work on an operating system (OS)
framework to build BibleTrans on top of. Actually I spent nights and weekends
on it since March, but now full-time.
2004 July 30 -- A command-line shell ran the first separately
compiled program file in the OS. It takes a lot of operating system to
support this much.
2004 October -- Took six weeks off to write and debug GeneScreen,
a Windows program. I guess it was a good thing to do, but I planned on
finishing it in 2 weeks. sigh
2004 December 24 -- The Finder opens and closes windows with
icons in them, and 2-clicking an icon runs the program, which opens its
own windows. The command line shell is gone. Memory is allocated dynamically
to programs as they need it. In other words, the system basically works.
2005 February 26 -- I gave up on making the operating system
a formal part of BibleTrans. It's too big. Instead I broke it off as a
separate
project, eventually to become the tool system I work in, but not holding
up BibleTrans. I will still write and test BibleTrans in Turk/2, but then
deploy it through a Turk -> C translator.
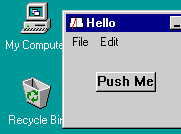
2005 March 17 -- Got a clean compile of my framework. There
are still a few parts not in yet, code I have not tried to use yet (I'm
not sure what I really want), but everything is in that I need to run my
little Turk/2 "Hello" program. The T2->C translator should be pretty simple,
just a (very) few syntactic substitutions.
2005 March 18 -- The framework now runs nicely on WinXP and Win95
(see screen shot above). This is a test program I wrote on January 1 in
Turk/2, then ran it through my translator essentially unchanged (I had
to swap a couple lines) and compiled on the Microsoft C++ compiler. Unlike
the
previous screen shots, which had the menubar in the Mac-like position
at the top of the virtual screen, this window has its own menubar like
a PC should. It works, too.
2005 March 25 -- Got a preliminary BibleTrans shell up with unit
tests for some of the framework functions. It now works in both the PC
(under the new framework) and MOS. It did find a number of previously undiscovered
bugs (some of them the same bug in both platforms, a consequence of copied
code), which I fixed. Unit testing is a new experience with me; it's wonderful.
Used to be that I just put everything together and made it work, but lots
of code doesn't get fully tested that way. This is slower (more code to
write) but better.
2005 April 1 -- Got data resources working as system calls in
MOS. Porting the code to the Framework went quickly, and the same test
code is cross-platform. I like this kind of progress.
2005 April 7 -- Got data resources and (minimal) shell program
all working together on PC in my framework. The resources turned out to
be messier than I expected, but writing test code was a big help in finding
the problems. It also helps to be doing this on my own software. There
were no resource bugs when I ported it to the PC platform, but it the tests
did turn up some date formatting problems there.
2005 May 4 -- The document viewer is in and working, complete
with Greek text and hot links to open secondary document windows. Porting
it to the PC went quickly, a few days after I had it running in MOS.
2005 June 1 -- The document viewer now does interlinear Greek
text in MOS, with popup menus to select which attribute lines to show or
hide. I spent three weeks designing resource data for interlinear Greek
text, then collecting public domain text and merging it with previous data
used in the Mac prototype. Making the program to format it was pretty messy
too, but it now works in MOS complete with popup menus to choose how many
lines to show.
2005 June 13 -- DragonDrop now works
in MOS. This was particularly tricky, with many pitfalls.
2005 June 21 -- It now all works on the PC, doc viewer, dragondrop,
interlinear Greek, nicely. There were some gotchas I had to work around.
We'll probably see more of these as we go along.
2005 July 19 -- It took some 3 weeks to build a credible data
file (and fix the many bugs in my display code), but I managed to import
the ABP definitions text from the existing
Mac prototype data, and to construct a "fake" Louw&Nida
lexicon, consisting of my own handmade definition glosses, also from
the Mac prototype. I have permission to distribute a binary version of
the real L&N, but that involves royalties and distribution tracking.
I posted a runable "demo" program, with everything
in it that works to date. It even works on Win95, but not quite as well.
2005 September 3 -- I got the tree viewer working on MOS last
week, complete with the verify operation,
which we use for consistency checks. Some tree editing functions are already
working: I can open and close nodes (show or hide subtrees), which automatically
links to off-page trees (and opens the corresponding window), and the code
to build a whole proposition from a single verb concept number seems to
work. There's a lot of complexity (over 3000 lines of code so far) so it's
going slower, perhaps finishing next week, then another week or so to port
it to the PC. At least it's progress.
In a relative scale of difficulty, it's pretty trivial to make a program
that lets you build arbitrary tree-structured data. It's a lot more difficult
to make the program such that you can only build semantically valid trees.
There will always be semantic nonsense the prevention of which we cannot
automate, but we can at least make the reasonable trees easy and the stupid
ones hard. Doing so is itself hard -- I call it the Law
of Conservation of Complexity, either the program is complicated,
or the user must do complicated things, which is why this tree editor is
taking so long to write. One of the things we need to do is anticipate
what kinds of things the user might want to do at a given time, then make
those things easy to do. On the Macintosh platform, the handy Enter key
(not to be confused with the Return key often incorrectly labelled "Enter"
on PC keyboards) was often programmed to "Do what I want to do here," whatever
that might be. The PC has no such culture of "easy to use" so the user
is usually compelled to go through numerous
unnecessary steps to accomplish simple default tasks.
Case in point: the user drags a L&N concept number from a list of
common concepts onto a tree node icon. If the icon is undefined, then obviously
the user intends for that concept to define it. If the concept is merely
a (near synonym) different idea of the same kind as what is already there,
the intent is to replace what is there with this slightly different idea.
On the other hand, if the new concept is a valid subtree of the node already
there (for example, an adjective to modify a noun), then the user obviously
intends it to be added as a subtree. In the case of noun and verb modifiers,
there are sets of mutually exclusive terms (such as verb tense or noun
plurality), and if the concept dropped on a node already has another member
of its set in place, the program can know to replace the previous subtree
with the new idea, so to make the verb tense future instead of present,
or the noun plural instead of singular. To make all this happen correctly,
the program must be aware of what nodes take what kinds of subtrees. I
guess if it were easy, somebody would have already done it.
2005 October 14 -- The tree editor is completely working on MOS
including Undo. There's a lot of complexity (over 4400 lines of code so
far) so it's been slow going. Undo is required for every possible edit,
to specify and save a sequence of steps (with data) to reverse that change,
but it went quickly because of the underlying support in MOS.
2005 December 19 -- I received a signed letter from the American
Bible Society (their web site --
both of them -- are pretty worthless) granting permission to distribute
an electronic copy of the
Louw&Nida
lexicon with the BibleTrans software. There is a small royalty involved,
so I must register who gets this full version instead of the freebie "fake"
version constructed from public domain sources, but this is the only proprietary
intellectual property that is essential to use BibleTrans; all other resources
we use are either in the public domain, or else are readily derived from
public sources.
2005 December 21 -- I spent a few weeks doing a compiler (for
$$, now finished :-) The tree editor is pretty much working on the PC.
I was able to import a tree file from the previous (Mac) version of BibleTrans,
found a problem in the imported data that I did not notice before, made
a change to fix it, then re-exported the file. I have not tested everything,
and there are still a few mostly cosmetic bugs, but it basically works.
It took a while to get here because Microsoft
VisualStudio is so hard to use. Worse than that, WinXP is quite flakey.
An important part of the way BibleTrans works is by direct manipulation
of graphical elements (otherwise known as drag-and-drop). On the Mac this
works so well I wrote my own DragonDrop package to retrofit the older (and
more robust) System/6 to do it; it's wonderful. Like so many other things,
Microsoft apparently bungled this one. Their drag'n'drop system calls are
not documented in the Win32 Programmer's Reference books I bought
a few years ago (used; no such documentation exists any more), but I Googled
(the only viable source for Windows documentation) "drag" and turned up
a 3rd-party tutorial (see Catch22)
with example code. It works great -- until
you try to drag across windows with some desktop or another app window
showing between: Kaboom! The VS Help search turned up three references
to this error message, all describing a work-around in some unrelated program
when it hits the same error, but no explanation of why or what caused it.
Google again turned up a zillion citations to the same error message, all
different programs that crashed with it, most with proposed work-arounds;
there was no overlapping common theme, all the fixes were ad hoc. One MS
programmer blog went into some detail as to the cause (he was trying to
trap keystrokes, not drag; this seems to be a bug deep in the bowels of
the system that infects fundamental operations), and was able to get around
it by moving part of his code to a separate thread. I tried that, and got
another undocumented error. Google again turned up a zillion different
places where people offered ad hoc work-arounds in all these disparate
places where it turned up, but one program listing said it means you need
to call a particular system call first. I tried that and got the same error,
but it was enough similar to what I was already doing that I found one
that worked -- except then the program just hung.
I started to think the Microsoft drag'n'drop is so badly flawed that
it probably cannot be made to work in a reasonable environment. I used
to wonder why all the documentation spent so much effort on what they call
Multiple Document Interface (MDI), which really means a giant window covering
up everything else, with subwindows to do the program work. Part of it
is because you really do want that menubar up at the top of the screen
the way Mac does it (see Fitt's
Law), instead of on every little window; but now I wonder if multiple
independent windows simply doesn't work in Windows. So I thought maybe
I get to write my own DragonDrop again. At least (unlike the folks in Redmond)
I know what I'm doing. I have already done two full (working) implementations,
one for MacOS/6 and one in my own MOS. Fortunately, the problem turned
out to be a compiler option set wrong. There is no clue that this
is a related problem, or even that it's a problem. sigh Oh well,
it works now.
2005 December 31 -- I spent a few weeks doing a compiler (for
$$, now finished :-) The tree editor is pretty much working on the PC.
I was able to import a tree file from the previous (Mac) version of BibleTrans,
found a problem in the imported data that I did not notice before, made
a change to fix it, then re-exported the file. I have not tested everything,
and there are still a few (mostly cosmetic) bugs, but it basically works.
John Watters, Executive Director of Wycliffe Bible
Translators, in his Dec.20 Christmas letter to the troops quoted John
Piper, "If we have not failed yet then we have not risked enough."
Elsewhere in the letter he cites the risk of Bible translation in dangerous
areas. I have a different risk. Those translators have a support system,
both organizationally (Wycliffe) and their supporting churches; I have
none. The Biblical texts Watters based his homily on concerned the submission
of the boy Jesus to his earthly parents. Was that a "risk" the All-Knowing,
All-Powerful, Sovereign God took to bring about our salvation? Hardly.
God knew exactly how it would come out. I (and those translators in dangerous
locations) take on a different kind of risk; God knows how it will
come out to achieve His purposes, but we don't. The other translators are
at risk for their very lives; I only risk financial loss. I already failed
once (hence the hiatus that brought me here), maybe that qualifies my risk
in Piper's eyes. I prefer to focus on the job to be done. Next year, God
willing, when this program is completely working, I enter into a different
kind of risk: trying to get a showing with the translators. I don't even
know how to begin. I have already mostly failed at that, too. God's strength
is made perfect in weakness. In the fullness of His time, it will happen.
Or maybe it won't. That's the risk, that I'm wasting my time and substance
on a project God has no intention of using. I hope and trust and believe
and act otherwise. Because I believe, as the church of Jesus Christ has
taught for nearly 2000 years, that the Bible really is the centerpiece
of our faith, and that we have an obligation to make it available to every
nation and tribe
and language in the world. Computers -- and BibleTrans
-- can help make that happen in our lifetime.
2006 January 19 -- The tree editor works
reasonably well on the PC. It's now time to get the Louw&Nida text
converted over to this new version of BibleTrans. I spent a week or so
fiddling with a HyperCard conversion program, which has now been running
pretty much continuously for the last two weeks, processing the text. Something
typically goes wrong every day or two, so I needed to keep restarting it
after fixing (or only attempting to fix) the problem.
The MacOS is really a paragon system, but being front-runner has its
downside: it does not multi-task well. HyperCard slows to 10% of its normal
execution speed unless it's in front, and my compiler only runs in foreground.
My MOS interpreter is too small and too slow to run these humongous programs,
but they aren't written in Turk/2 anyway. That needs to change. The PC
framework is reasonably robust, but C is not, and the conversion from T2
to C lets a lot of bugs through that a reasonable compiler can catch. The
solution I came up with is to retarget the Turk compiler to generate 68K
Mac code (simpler than PowerPC, plus I know how to make classic Mac applications
-- Apple was pretty tight about telling people how to create PowerPC binaries,
and the 68K emulator is pretty fast), then port the framework over to the
Mac, but written in T2. I can do this while HyperCard grinds away at the
L&N text, bringing HC to the front whenever I pause to think or otherwise
don't need to be typing. As of yesterday the T2 compiler makes pretty good
68K code, and I have a simple HyperCard application builder that creates
a 2-click Mac program from the compiled T2 in a single click. I figure
maybe another week and the framework will be working on the Mac. Then I
can start rewriting all those HyperCard programs in T2, so they can run
fast in background while I do other things in foreground. One of the rewrites
(probably not this year) is to retarget my
TAG compiler to generate T2 instead of C, so it can run in the background
too. Once things are converted and working reliably, I can start seriously
migrating them to the PC, for another 5x speed boost (2GHz instead of 400MHz
emulating 68K). I figure the long-term savings (what takes a week in HC
to rebuild the BibleTrans data files here on the Mac, might be only one
day on the PC which is otherwise turned off) justify letting HC run slower
right now while I work on the framework. I expect to rebuild the data files
dozens of times before this gets released.
2006 February 1. The Louw&Nida text conversion finished about
4am this morning, but with serious flaws, a lot of missing Greek words,
stuff like that. They are there in the original files, they just got lost.
Either I must spend a lot of time hacking the HyperCard program to find
and fix the bugs -- and a lot more time waiting for it to run to the problem
-- or I just bite the bullet and rewrite the conversion program in T2 now.
Sooner or later I need to do this anyway, because HC does not run on any
modern computer. Let's not waste any more time on obsolete technology.
With some perseverance I can get the functionality I need up in 68K T2
pretty quickly, maybe even by the end of this week. Nothing will ever be
as easy to use as HyperCard, but T2 should run substantially faster (especially
in background, while I'm doing other things on the computer) and especially
when I port the tools over to the PC running the same framework. Oooh,
controlling my own tools is soo much nicer than the alternatives.
sigh
2006 February 10. My framework validation test suite program
runs correctly in the new Mac (68K) version of the framework. That means
I can start rewriting the file conversion tools (and just about everything
else ;-) in Turk/2 and run them at native machine speed here on the Mac.
There are surely some bugs I didn't hit that will need fixing, but things
should go a lot faster now.
2006 February 18. HyperCard is wonderful. It's also as dead as
the MacOS. Most of my data crunching document preparation code was done
in HC, but the really long runs took days -- and had to run in foreground,
because it ran 10 times slower if it wasn't the front task. One of the
features of HC that I use a lot in preparing the data is its very simple
string sort. I was worried about making something that easy to use in Turk68,
and especially how fast it would go. So I read up on QuickSort in Knuth's
classic Sorting Algorithms, but he admits that nearly sorted files run
in N2 time (the best sorting algorithms
are NlogN), and it's rather complex. Instead I wrote a modified
MergeSort, which has a guaranteed NlogN time worst case,
and (in my modification) linear time for already (nearly) sorted data.
I don't know what HC does, but my sort is screaming fast: 100,000 lines
of worst-case data sort in 1.1 seconds. It took almost 2 minutes just to
build the data. HC sorts the same data in 5 seconds (about the same build
time), but HC is native PowerPC code, while mine is running in 68K emulation.
And mine works just as fast in background -- well, maybe half as fast,
but not 10% like HC -- while I'm doing other things on the computer. With
a little tweaking, I got the build time down to 5 seconds, so now I'm doing
in T2 in 6 seconds what it takes HC on the same computer to do in over
2 minutes. The 3-day runs (which can only get longer as I add data), after
rewrite in T2, should finish in maybe 3-6 hours.
For those unfamiliar with computational complexity terminology, "linear"
means that when the file size doubles, the runtime doubles; for N2
the runtime goes up 4x for a doubled file size (that doesn't look so bad
as when your file gets 10x bigger, the runtime gets 100 times longer).
LogN refers to the logarithm base-2, essentially the number of bits
in the number representing the size of the file. If you double the file
size, a logN algorithm goes up one unit. NlogN is
slightly slower than linear, but not by much: my sort makes 13 passes over
a 10,000 line file (130,000 compares) and 16 passes over a 100,000 line
file (1.6 million compares). The worst kind of computational complexity
("NP-hard") is exponential, where going from 10 items to 20 items takes
1000 times longer; large files are just plain impossible. The best kind
of algorithm is constant time, which does not take longer for larger data
files. Yes, there really are (near) constant-time algorithms, but not many.
I have about 7500 lines of HyperCard code to convert (perhaps not all
of it), which is a somewhat higher level language than T2, so I get maybe
20% more lines of T2 than HC. I did 6000 lines of framework in maybe 6
weeks, so this conversion could take a couple months. Hopefully less, because
the algorithms are not changing, just the spelling. I gotta be careful
not to think too much about the size of the job ahead of me, perhaps concentrate
instead on getting something to work. One step at a time.
2006 March 9. It turns out all the intermediate
files and HyperCard (HC) programs I saved from building the HC-based (Mac-only)
prototype of BibleTrans 6-8 years ago, are incomplete. At that time I was
constructing everything out of data exported from Translator's Workplace
(TW), a CD of tools made available by SIL to people doing Bible translation.
I spent a lot of time extracting the text and formatting of the Greek and
English Bibles and the Louw&Nida lexicon, for hot-linked display in
BT. The files on that CD are not in very good condition, and I had to hand-patch
a lot of flaws, mostly where the formatting was just plain wrong, but also
some missing text, which I recovered from other versions of the text (such
as books). Now that I'm trying to get HC out of the process, I need to
recreate those corrections, or else take the corrected text as my base
point. I asked (twice) about getting an approved file of L&N when the
American Bible Society licensed it to me, but they did not reply. So I'm
using my corrected text.
In the case of the Greek text, I have an agreement in principle from
the German Bible Society to get it licensed, but nothing signed yet. However,
I want to post a public (trial) version of BibleTrans to the internet,
which I cannot do with licensed materials, so I'm working on getting the
Greek text with interlinear English glosses and lexical forms constructed
from public domain materials, again leaving HC out of the process, so it
can be repeated (maintained) by other people. The Greek text itself I am
building from the 1881/1885 Wescott&Hort edition, which is public domain
and available on several internet sites. Some of those sites give English
glosses and/or parse codes, which are probably not public domain, but the
parse codes and lexical forms represent (mostly) common knowledge, which
is public. To establish that, I am comparing the data from three independent
sources, and using only those items where there is agreement. One of those
sources is the TW file with all its flaws. sigh
For people worried about such things, this is all perfectly legal. The
license agreement I signed for TW restricts it to Bible translation, and
that's what this is. I'm only using the data from the CD for developing
Bible translation software, and distributing only such parts of the data
that I have a signed license to distribute or else is in public domain.
I also have a properly licensed version of the GramCord Greek text that
I am using for comparison and not otherwise. When I distribute Greek text,
it will be properly licensed, or else in the public domain. The English
glosses on the public version of the text comes from the Strong's lexicon
(which is in the public domain), or else from my own (and paid-for) work,
which I therefore own. Putting all this together is a pretty hairy program,
which is why it's taking so long.
Endemic in this whole project is the inherent problem of taking flawed
human documents -- in this case the machine-readable Greek text and lexicon
-- and converting them to a precise and consistent form for the computer
to use. People looking at these documents can just muddle through; machines
are not smart enough to muddle -- unless you tell them how. I spend a lot
of time these days telling this program how to muddle through textual problems.
2006 March 24. It took a whole week, but I finished working
through the Strong's Greek dictionary. The file I'm working from was handmade
(probably from a book) and full of formatting errors, which made the program
work very badly. So I wrote a quick HyperCard program to go through the
file and present the definitions one at a time, with all the best choices
for definitions numbered. Then I sat here and selected the best -- or in
some cases retyped the intended definition from the other words that the
program was not able to pick out. 5624 definitions. Whew! Now this result
(which is my work + public domain) can be used to give a credible gloss
(English translation word) for each Greek word in the New Testament. There
are better ways to get a Greek-English interlinear, but I do not know who
owns the rights, so to license one.
Anyway, so now I also have this T2 program that compares the Greek text
from a variety of sources to extract the public information. It uses this
new Strongs summary for the English -- except for those Greek words already
manually tagged with Louw&Nida numbers and for which I already have
glosses. See March 9 report (above) for more details.
The program takes about two days of continuous running to complete and
collect a word list sorted by frequency; I will run it over the weekend
starting tonight.
2006 April 27. All of the document preparation code that I had
in HyperCard is now running in T2 (literally, as I write this). It will
take about 20 hours to process the Greek vocabulary (running right now)
and then another 20 to convert the New Testament text to the numbers, then
another 9 hours or so to prepare the English documentation text (most of
it has not yet been ported over from the Mac version of BibleTrans and
revised). Meanwhile I have started retargeting my T2 compiler to C, so
I can port everything over to the PC. I have a HyperCard hack that does
a poor job of it, but I'm trying to get Apple products out of the loop.
T2 runs faster than HC, especially in background, so I don't lose the use
of my Mac when I have stuff running. This is a big advance from a month
ago. Sure is nice that electric power is reasonably reliable: I lost power
for a few seconds during a thunderstorm a couple weeks ago, but other than
that the computer has been running continuously the whole month. I put
the long runs on for overnight and across the weekend.
2006 May 9. I just tonight finished building the (public domain)
Greek NT and "fake" Louw&Nide lexicon into the data file format my
program uses, exactly one month after deciding to do this completely in
Turk/2. Because the long runs now run reasonably fast in background, I
also got the T2->C compiler working and have about 30% of the framework
originally written in C for the PC converted back to T2 (which then compiles
into C again ;-) The advantage of doing it this way is the inherent robustness
of T2: my compiler catches a lot more of the silly mistakes every programmer
makes, so debugging can be much faster.
2006 May 26. The revised PC version of the framework now works,
and although the T2 compiler still runs on the Mac, all Apple software
is out of the loop. The document preparation program that was working on
the Mac now runs on the PC too. I didn't transfer all the files over, but
it does build the binary database, which is the final step. Alas, when
I ran my framework verification test, the long string-handling part which
takes 17 seconds on the (400MHz) Mac in emulation, took 5 minutes on the
(2GHz) PC in native code; it should have been 15x faster, not 18x slower.
I turned on full optimization on the Microsoft C compiler, and the same
process now takes 25% longer. Go figure. I guess I will continue
to do most of the work on the Mac. That's what I get for having nothing
good to say about PCs -- oh wait, that's why I have nothing good
to say. Anyway, my previously working developmental version of BibleTrans
compiles into clean C/C++ code and starts up, but still has some bugs.
Hey, it's progress.
Also progress: the German Bible Society agreed to license the current
text of the Greek New Testament for use in BibleTrans. I now have the official
text file, ready to build into the data for a licensed version of BibleTrans.
I will continue to develop the public domain text for posting online, which
I cannot do with the licensed text.
2006 June 13. Interim report, I am alternately thrashing bugs
out of my framework on the PC, and fixing problems with the data files.
Things shouldn't be this hard to do, but I did at one point describe working
on the PC in C/C++ (after being Mac-only for two decades using better tools)
as something like "falling
out of Heaven and landing in -- well, it's not Hell, but you can smell
the sulphur." No idea how long it's going to take to get things back
up to where they were in January.
2006 July 24. I spent a lot of time trying to get the Tree editor
working again, but we seem to be there. The translation engine is in and
seems to work, complete with a visual debugger window, and the window displaying
the result looks good.
2006 August 2. Active image elements in documents now basically
work. I've only implemented popup menus and three kinds of button (push
button, checkbox, and radio button group), but they all format and function
nicely. GrammarWhiz (formerly GrammarGuru, but some cultures have religious
problems with the idea of "guru") needs some fancier items, but it's now
a simple matter of programming, not an unknown risk.
2006 September 25. Has it been that long? Wow. I spent a lot
of time making active image elements work nicely (not done yet, but close).
I just today registered a new BibleTrans.com
domain and uploaded the information that used to be under IttyBittyComputers.
2006 October 21. The active image elements
that I need for grammar specification all seem to work. Now I can start
fitting them together to create a language specification -- well, I've
been saying that for two+ weeks now, because I keep hitting holes in my
understanding of how this needs to work. However, it is nonetheless real
progress! The Mac version does not have this (it was in process when things
blew up). (2006 November 30) Still working on it, but the specification
now compiles into code that runs; I just don't have a real grammar yet.
But it does take input for the lexical items needed in the selected (John
3:16) Tree and compiles them to credible code.
2006 December 23. I think the Enemy is laying out the big guns
for me. I have spent an obscene* amount of time fixing residual bugs in
GrammarWhiz (see Oct.21 above), then my mother went
into the hospital a couple times, which blew away large chunks of almost
every day... and I'm still having trouble getting a clear understanding
of how these grammar specification elements are going to work together
to produce an English sentence like "Won't John have already been coming
when we get there?" Notice the negative contraction, three helper verbs,
the syntax of each determined by preceeding words, embedded adverb in the
middle, subject-verb inversion but only with the first helper, all very
messy -- and English is not a hard language compared to what this needs
to work with. Not to mention, I found a zillion more bugs today in the
document file generator. sigh At least my T2 compiler produces
code that runs efficiently in background, so even though it's a 12-hour
run, I have full use of the computer for finding and fixing bugs while
it's running.
* Well maybe the amount of time I am (still) spending on debugging shouldn't
be so surprising. This program is incredibly complex, and probably has
no right to work at all. Uli Kusterer sent me an interview questionaire
on my work in HyperCard and CompileIt; one of the questions asked what
impressed me most about my program. I said I don't usually get impressed
by my own work, but on further reflection, I think I really am impressed
that the thing works at all!
2006 December 30. I wasn't sure I could pull it off, but I believe
I successfully encoded the English verb phrase using my new GrammarWhiz.
I still have pronouns and subject/object parts of speech and subordinate
clauses to do -- and there are a zillion known bugs in the code -- but
the verb was the one element I didn't know if I could even do it. I might
have it translating in a couple more weeks.
2007 January 25. I have most of an English grammar for John 3:16
encoded (no pronouns or subordinate clauses yet) but it compiles and the
translation engine starts to execute. There are major bugs to fix, but
it's working! No output text yet, maybe by next week. Update January 27:
got some output, "God love people" but no tense or articles or adverbs...
February 3: I've got all the words out, and the verbs are inflecting correctly
-- except for passive -- but it does not yet know that English possessives
suppress articles.
2007 February 10. It now knows how to turn the direct object
into a subject for passive voice -- getting to the necessary information
in time to do that turned out to be tricky -- but my grammar does not yet
know that possessives and proper nouns and certain category adjectives
(like "all" or "every") tend to suppress English articles. I haven't even
started to do pronouns (including relative pronouns).
Here is John 3:16 so far today. The pronoun generator will be substituting
pronouns for the nouns in red, but I expect
that to take most of next week to get it in and working:
God greatly was loving the people therefore God
gave God's unique son to the
people so that every person that the person
is trusting the son might not be destroyed but the person forever will
be living
2007 February 26. Success! The program now correctly translates
John 3:16, complete with reasonable pronouns and verb inflection:
God greatly was loving the peoples therefore he gave his unique
son to them so that every person who is trusting the son might not be destroyed
but the person forever will be living
I uploaded a zip file of this developmental version,
but it crashes everywhere except Win95.
2007 March 6. Utter failure. My program runs fine in the Microsoft
debugger, but not as a standalone program. I can't ship a $1000 copy of
VisualStudio with every copy of BibleTrans. The VS debugger is not as powerful
as the Apple MacsBug debugger, so I have no way of tracking down the problem.
Maybe a good Windows debugger exists, but I don't know where nor how to
get it. Maybe VS can do the job, but it's essentially undocumented, so
I don't know how to drive it, except what I can figure out by randomly
trying things.
My best guess is that the problem is a wild pointer write, such as the
programming language C encourages. The BibleTrans program is written in
T2 and compiled to C, but the framework connecting my code to the Windows
operating system is hand-coded C. The bug could be in my T2 compiler, or
it could be in the framework, or even (but much less likely) in the Microsoft
system or compiler. About the only way to fix it is to throw everything
away and start over, hoping I don't reproduce the bug in the new version.
I can reduce the probability of that by eliminating system threads from
my code.
2007 April 13. I completely rebuilt the framework and redid the
T2C compiler so I manage my own threads without relying on C threads. This
has the advantage that I don't need to convert so many pointers into integers
and back, a notoriously unsafe practice. The new framework basically works
-- my test suite has over 100 specific tests and runs with no errors. That's
all still in the debugger. I recompiled BibleTrans into this new framework,
but the Microsoft compiler was still compiling it after four hours. I have
no way of knowing if the file is just too big for available memory, so
it's thrashing, or if the compiler was actually hung. A 4+hour compile
step makes debugging problematic, so I restructured this into multiple
files, which I have had very bad luck with in the Microsoft compiler. Then
it still didn't run correctly, so I built
unit
tests (a very tedious but rigorous process) for almost everything.
That turned up a lot of failures that I was able to fix. So it's back to
recompiling -- veeerrry sloooowly. sigh Besides that, it still works
in the debugger and crashes when compiled as a standalone. sigh
2007 April 20. I put in a lot more code to get away from undocumented
and untestable Microsoft code, but it still works in the debugger yet crashes
when compiled as a standalone. I have no idea how to find the bug that
makes the "release" version crash. However, I noticed that the debugger
version also runs without Microsoft VisualStudio installed, so I
uploaded that April 16. Today I fixed a file problem and an output
display bug, and uploaded new version. Compiles are very slow, I think
I will work on removing unnecessary segments to cut file size.
2007 April 28. I successfully reduced file size by about 25%,
and uploaded it. Then I ordered more RAM
for the computer. 3x larger program size should not compile 200x slower
unless the compiler has run out of working memory and is thrashing to disk.
The rest of this week I spent fixing smaller bugs and actually got into
writing more documentation. There's still a lot to do before
it's ready. sigh
2007 May 17. 1.2 gigs of RAM only went 20%
faster, so it can't be a thrashing problem. Maybe it's another one of those
things that Microsoft did badly. Who knows? Since the compiler change that
resulted in these larger files did not cure the crashing problem, I went
back to using the Win32 threads instead of my own. Besides smaller (much
faster) compiles, this also gives much more readable C code. It sure is
nice to have that 10-second compile time back! Also, my own memory management
is catching some run-time errors that Microsoft's VS missed. Now I'm ready
to start updating the grammar to translate the Philippians trees. The program
found (and I fixed) several tree coding errors that previous manual checks
did not catch.
2007 June 23. I started updating the grammar to translate the
Philippians trees, and ran into numerous problems. Some were program bugs
easily fixed, but a significant number of the difficulties came from my
resolve to use only the tools that I want to be available to working linguists.
I couldn't do it, so much of the past month has been upgrading the grammar
editing tools. I'm not done yet, but I'm confident that this effort will
be successful. I already used some of the new tools to identify why my
John 3:16 stopped working (a noun phrase rule somehow got turned off).
2007 June 30. John 3:16 now translates correctly again, after
numerous bug fixes. I'm still not completely free of my private debugging
tools for finding grammar problems; I wonder if I'll ever be? We'll see
when I get back to Philippians, next week.
2007 July 20. Php.1:1-2 now translates reasonably well, after
numerous bug fixes and improvements:
from Paul and Timothy to all God's people
associated with Christ Jesus with elders and deacons , grace and peace
are being from our Father God and Lord Christ Jesus to you
It doesn't do a very good job with commas; I think there is some human
judgment in that, which the computer will never do very well. Also, we
are used to the Greek order, "grace and peace to you from God..." while
the translation engine -- actually this particular grammar -- normalizes
everything to put the source before the destination. We could write exceptions
for OpenBlessing, but why? It's understandable enough. We have the same
kind of word-order strangeness in "the Lord Jesus Christ". That happens
in the Bible often enough to be worth putting a special rule in to handle
it. Strictly speaking, "Jesus" is his name, and "Lord" and "Christ" are
titles. Titles normally come before the person's proper name. However in
modern English "Christ" has turned into a surname, like "Jones" or "Smith",
so it should follow the given name "Jesus".
2007 August 11. Shortly after getting a reasonable
translation of Php.1:1 I decided to prepare a new download.
sigh
A full build of the Greek New Testament from public domain sources takes
just under a week (nonstop) on this 400MHz Mac. I tried porting the program
over to the 2GHz PC and running some of it there, but it took some three
to five times longer (I finally killed it the third day). This is the same
source code, written in T2
and compiled to C++ (which is then compiled on the Microsoft VisualStudio
compiler to x86 machine code); on the Mac I have another T2 compiler that
produces 68K machine code, which runs native on the original Macintosh
computers but the PowerMac runs in emulation, typically 3-5 times slower
than PowerPC native code. In principle the PC should run things 20 times
faster than my emulated 68K code on the Mac. I can't explain the profound
slowdown except to blame
the C++ language.
So I'm still running everything on the Mac. The first run had some files
mixed up -- I tried to bypass the step of merging the Greek text from three
sources, but missed some critical intermediary files -- and produced no
usable output text. The second run worked properly, but I had bungled a
couple episode titles in the second chapter of John, so most of John (including
my flagship 3:16 text) turned up missing. You can't tell these things until
the text is all loaded and you run the program and ask it to display the
Greek text you are about to translate, and it opens a blank window.
You might ask "What's wrong with the data I was using last year?" The
licensed Greek text is divided into sections (I call them "episodes") which
are the unit of translation in BibleTrans; I use the same episodes. The
public-domain Greek text has no such divisions. I originally broke it into
10-verse sections, but earlier this year I paid a high-school student to
type in the section headers from the ASV (1901) Bible, and the translation
program is already using those new episode boundaries for verse lookup.
It wouldn't do to link a verse in the Philippians database Tree and have
the Greek text for 2 Thessalonians open.
While waiting for the build program, I wrote parts of the program that
I was previously procrastinating, like the part that does morphological
rules and non-Roman fonts, which now works (except it doesn't display properly
yet).
2007 September 4. I uploaded a new version
of the program last week. It translates John 3:16 and Philippians 1:1
into English. Php.1:3 is taking a little longer, and I found another flaw
in the Greek text requiring another rebuild, which finished yesterday.
The morphological rules now work properly -- I cloned my English grammar
and added some rules to move the first letter of each word to the end and
add a suffix to make PigLatin. I will put that in my next upload, after
more of Philippians translates correctly. I need to figure out how to insert
a default "it" subject for impersonal verbs. And then put in a zillion
lexical rules. I'm sure glad I don't have to do the whole NT.
2007 September 18. I'm still a programmer at heart. Creating
"G-Whiz" grammar rules is a lot harder than just writing
code to do it. I have all the lexical rules for Php.1:3-11 in, and it mostly
translates OK (albeit somewhat wooden), but there are gaps and strangeness.
Like the "glad" part of "I am glad..." is missing. I had a pretty tough
time getting pronoun possessives to come out correctly in front of the
noun, "my God" instead of "God of me" so that the other possessives still
come out with "of" after the noun. I don't have a lot of confidence in
being able to explain this to the linguists who need to use it. sigh
A couple of fairly large side trips (maybe two months together) need to
be done eventually, and may make it easier to finish up Philippians. "Agile"
programmers call it "refactoring" when they do this kind of stuff in small
increments; I think they are in denial about the need for large-chunk redesign
like this. Their problem, not mine.
2007 November 1. I threw my English grammar away and started
over, while writing up the steps as user documentation. The result is cleaner
than the previous version. I hope to have the whole thing uploaded
by the weekend.
2007 November 29. Philippians 1:1-11 translates pretty OK (see
it here). Punctuation is goofy, and some words
are out of order. I probably won't fix those bugs.
2008 January 3. Philippians 1 translates (see it here).
1:28 has some duplicated propositions in the semantic tree, and there are
other strange semantic encodings that make decent translation difficult.
Obviously I needed to spend more time reviewing this when it was being
built, but not having a working grammar was the biggest problem. Getting
just his chapter to translate has taken far longer than I expected, and
chapter 2 looks to be as bad.
In view of these unexpected difficulties, plus my inability to connect
with a non-European language speaker for doing another language translation,
I'm beginning to have doubts about the viability of BibleTrans. This I
can do:
a. There are parts of the software that are incomplete (Greek
text tagging, Unicode support, and getting the documentation up to date);
I can finish them up.
b. (Hopefully with help from E.Miles) I can repair the problems in Php
(and maybe also Luke) tree.
c. I can keep looking for a non-European language speaker to work with.
I'm guessing 6-12 months to bring it to a stable condition, and then if
something doesn't happen, go look for an honest job.
My web host has stopped making their services available to me, so I
also need to get a new host before the current contract expires. All of
them seem much less accessible (lower security) than when I first did this.
2008 January 24. I have not yet figured out how to do Unicode.
Example: Amharic has more than 256 different glyphs (36 consonants * 7
vowels, plus 20 numerals and 6 punctuations); many can be done by jamming
a vowel curlicue onto the basic consonantal form, but not all: the consonant
shape changes in many cases. I can probably do it and make it fit in my
222-char limit, but not as easy as importing the whole font from an installed
Unicode should be.
Otherwise all the BT features are now in (still have some bugs to fix).
There is a lot of documentation to add and/or update.
I'm also building an alternate document database with the licensed texts,
but there are numerous inconsistencies which require special ad hoc fixups.
sigh
I now have a new domain name (BibleTrans.info)
and web host up. Maybe next month I will start trying to get the domain
registration and hosting for BibleTrans.com
transfered over to this new host. If I succeed, it will go offline for
a few days or hours; if I fail, I may need to wait until the name registration
expires and try again (possibly several months).
2008 February 15. I decided that explaining "How BibleTrans Translates"
is easier if I just keep my existing document structure, but it depends
on having working breakpoints. So I put them in. Now I just need to get
the explanation updated, and I'll have a new upload. Meanwhile, the computer
is busy rebuilding the entire Greek text using licensed data. It will probably
take most of the month to get it right. My new laptop may arrive by then,
so I can spend some time making a demo video (laptop is specified to make
that easy).
2008 March 3. Other than a dozen or so documentation topics I
have not yet written, and some cosmetic defects that probably won't get
fixed, the software is finished. Except I ran into some kind of conflict
between the licensed Greek text and the public domain version, which corrupted
the words in the PD version of Luke. At least I think it was a conflict.
I decided to get the Luke semantic trees in and ready to use while waiting
for the licensed text to format (a 5-day run still going as I write this).
The trees have problems too. The program crashed importing them. I guess
I won't be uploading the "final" version for a couple more weeks, maybe
longer if I can't find the bugs.
2008 March 29. I found some bugs in the "English Grammar Step
by Step" tutorial that would have made it fail. I guess nobody is looking.
sigh
The Luke trees are full of bugs I need to fix, and I have not done any
more in Philippians, but I want to upload this revised Public Domain version
now because of the tutorial bugs. Next week I'll work on the Luke tree
problems. I was unable to get with Elizabeth Miles to fix the Philippians
problems, so maybe I'll just cobble something together there too. sigh
2008 April 10. The licensed version is stable. Only one person
is nominally serious enough to send it to, but I uploaded a compatible
freebie version at the same time. Still no opportunities for doing a non-European
language grammar yet. So I wait on God's timing.
2008 June 18. I found and fixed a minor bug in the code, then
spent some time repairing the three places in Philippians where the trees
were inconsistent. This required some new L&N concept clone(s), which
meant a full data rebuild. Done and uploaded both freebie and licensed.
I may get an opportunity to encode the Awa (non-European) language grammar
later this year, so I started looking at the Awa linguistic resources.
It is admittedly incomplete, and the organization is quite different from
the form BibleTrans needs it, so I probably need to wait until I can spend
time with the linguist who did the Awa New Testament.
2008 September 27. Started a hack tutorial "Awa by the book"
based on the Awa grammar and dictionary sent me by Alan Buseman. The book
grammar is explicitly "preliminary" so it's rough going. Alan scanned the
book, then I spent a couple weeks cleaning up the OCR
text.
2008 November. I went to Waxhaw and spent three days with Alan
Buseman and the Lovings working over my understanding of Awa. I got a much
better feel for how to structure Awa sentences than I could infer from
the books Alan had previously scanned and sent me. I have a serious problem
composing paraphrastics in BibleTrans; this will take considerable inventiveness
to overcome. I should have been thinking about it more all along. Alan
also urged me to build in default grammars that cover the basic VSO, SVO,
and SOV language types. I decided to do that before tackling Awa again.
Fixing bugs while awaiting Alan's input.
2009 January 15. Built basic VSO, SVO, and SOV grammars for BibleTrans
to plug in when you start a new language. Started rewriting "English Step
by Step" tutorial, based on the base SVO grammar. It's a lot simpler to
explain, and you can get immediate gratification within a few minutes,
a big plus!
2009 January 24. Uploaded a hack with the new grammar defaults.
The docs are all wrong, y'all need to wait for my rewrite, probably a couple
months.
2009 February 12. Received permission from David Austin at Bible.org
to use the NETBible as a resource in BibleTrans. Downloaded the source
files. This has awesome critical apparatus, a total of over 60,000 notes
for the whole Bible. That's too big for my present encoding, so I'll use
just the New Testament at this time. Encoding the text should keep my computer
busy running continuously (night and day) for a couple months. The whole
encoding takes just a week or two, but I keep finding undocumented tags
and other strangeness which requires that I fix my code then run the whole
thing over.
2009 April 16. NETBible now in and looking
good. Finished revising English Grammar documentation to conform with new
SVO defaults. Starting to redo Awa with SOV default.
2009 June 1. Awa is still using up rules faster than I hoped;
I may need to open up another block of conditionals. Longer compiles are
now triggering "dead-man" interlocks and inter-process race conditions.
It looks like I need to take time out to overhaul my framework.
2009 June 15. My framework and T2 compiler now does proper reference-counting
on all allocated memory, so garbage collection is (mostly) automatic. As
a result, the deadlock problems are gone, and translation is back where
it should have been three weeks ago. It's slightly (but not noticibly)
slower, because the compiler reference-counts all pointers, including those
I (as programmer) know don't need it, but at least it seems robust. I uploaded
a current working version, although the Awa grammar and tutorial is only
half done.
2009 August 18. I met with the Awa linguists and we worked through
their published John 3:16 translation. I have a lot of corrections to make
to my grammar to get something like this out. While waiting for the meeting
I also made some cosmetic improvements to the structured output display,
which now works more responsively with large data. I uploaded a current
working version.
2009 September 16. After a few more (email) consultations with
the Awa linguists, we have a working John 3:16 translation. The current
working version will be uploaded as soon as the documentation build finishes
(in a couple days).
2010 February 1. I lost the domain BibleTrans.com.
The host I had it transferred to bungled the transfer, so the domain was
never re-registered and properly renewed with the new host. When it expired
without my knowledge, a cyber-squatter snapped it up to hold for ransom.
That's the most charitable interpretation I can make of the situation I
learned about three days ago. Another possibility is that the domain was
stolen, but the facts don't quite line up for that scenario. My new host
is disinclined to be helpful, so I have no alternative but to wait until
the domain expires in December, and if the squatter is given no reason
to pay for another year, I might be able to get it back. Providentially
I had the foresight to register BibleTrans.info
with a different registrar, so I still have that domain.
2010 March 2. I have not been working on BibleTrans for the last
few months, mostly because I have some paying (and paid) work to do. It
stalled today, so I'm cleaning up the BibleTrans documentation while waiting
on my client's decision.
2010 April 30. The pastor of the local church invited me to make
a presentation. I tweaked BibleTrans to display large fonts (so they would
be visible on the projection screen), now in the most recent BTdemo
upload. Thumbnails of the presentation slides, and my transcript can be
viewed here. The actual presentation was
rescheduled to 2010 July 11.
2010 May 17. I exchanged emails with Aretta Loving and another
linguist working in PNG. They would like to use BibleTrans when it is ready,
but they are not prepared to be a part of its development. I'm unable to
imagine anybody else in their position -- let alone a dozen of them --
trying to convince their sending churches to fund something so altruistic,
especially when it seems as risky as BibleTrans. And especially in today's
economy.
2010 July 12. The presentation at
Berean Baptist Church last night was well-received. Dr. Greg Christopher,
who is Dean of the graduate school at Baptist Bible College in Springfield,
promised to "brainstorm" ideas for moving this forward, but nothing came
of it. He has a full plate with his own God-given agenda.
2011 January 14. I now have the Mac version of my Turk/2
compiler upgraded to support OOPS and mostly working
(I still have a couple minor bugs to fix). I need to port the alterations
over to the PC version of the same compiler, but I can now begin revising
BibleTrans to use the new features, and especially to expand the table
sizes that proved so limiting heretofore.
As of May, I'm having trouble getting up motivation
to continue development on something that now looks like it will never
be used. I'm a known and proven failure at writing fundable grant proposals.
I am essentially cleaning up the T2 tools, so I can post everything as
"open source" in case somebody in the future decides to care after I'm
gone.
2011 December 28. C is now completely out of my Mac 68K T2 compiler
(including the TAG compiler), so everything runs in background now. It's
about 2x slower than the C version (due to the emulation of 68K code),
and runs another 2x slower in background, but it does run in background,
which the C version did not. I get to use my computer for other things
while it's compiling. Recompiling the compiler is about 3 hours if nothing
else is happening; that's a lot of computer time to lose, but I no longer
lose it. Yay!
2012 April 9. I decided to do the Luke 13:8 thing, finish this
up this year. OOPS is working, and I tried
to get a reasonable integrated development environment (IDE)
up by Easter, but these things always take longer than planned. At least
I exercised (and fixed) a lot of the language and library that BT needs
to be using. Two things need to be done:
(1) Fix BibleTrans to have bigger grammar tables and use OOPS,
which will then be running on my Mac (where development is easier than
when I was compiling everything to/on Windows), then
(2) Upgrade the T2->C compiler and get everything running on the PC
again.
Then if God wants me involved in doing something with it, fine. Otherwise
I'll do something else.
2012 April 27. The BibleTrans main program is up and displaying
text and pictures. I'm still working on upgrading the other processes (grammar
edit, tree display+edit, translation engine) to get them to compile in
my revised framework. The file generator already works. Today I started
a new BibleTrans Rationale document, explaining
how everything works.
2012 May 3. The program I have been using to build the data files
for BibleTrans is crashing partway through the process, probably due to
what I call "flying bits" (a bogus pointer, so data gets stored in a random
location in memory). These bugs are very hard to find, and my compiler
mostly prevents them. Anyway, so I'm trying to figure out where it went
south, and happened to see in the intermediate data numerous words that
look like misspellings. The data files I got from other sources have numerous
typing errors, and I guess I haven't found all of them yet. My own documents
also have mistakes. I spent most of today fixing their documents and mine.
2012 August 18. I keep finding (and fixing) problems in my T2
compiler and the framework (like an operating system, see MOS),
but the OOPS part is mostly functional and BibleTrans
now (sort of) runs on my Mac. Today I uploaded some of the new design
documents I'm working on while waiting for the compiler.
2012 September 22. BibleTrans still "sort of" runs on my Mac,
but the translation engine fails in various ways. It produces output with
missing or wrong words, or wrong inflection, stuff like that. I'm still
finding and fixing bugs in the framework, but in trying to track down these
bugs I discovered that (like Robert
Browning said of one of his sonnets) I no longer understand how the
grammar and the data structures work. I'm spending a lot of time figuring
out, and then writing up what they do. Today it's the English
Grammar.
2013 March 18. I took a couple months off to produce my
sister's cookbook. When I got back to BibleTrans I had lost all my
contextual memory of what I was doing, so I set it aside to rebuild the
Turk/2 compiler that translates to C++. The compiler seems to be working
and builds C++ files that compile in VisualStudio (Microsoft's C++ compiler
for Windows) without reported errors. Today I start working on making the
revised runtime framework actually work.
2013 April 12. The T2C compiler seems to be working and builds
C++ files that compile and run correctly in VisualStudio (Microsoft's C++
compiler for Windows). Today I start working on making the T2C compiler
compile itself on the PC. The goal is to upload all the sources as "Open
Source" so interested people can use it after I'm gone.
2013 May 7. The T2C compiler now seems to be working and compiling
itself on the PC. I uploaded the sources hereso
interested people can use it both now and after I'm gone. I guess I'm back
to working on BT proper again.
2013 May 30. It turned out that BT is a tougher customer for
the revised T2C compiler than compiling itself, so I had a lot more bugs
to fix. I probably won't upload the revised T2C compiling itself and BT
until BT (as revised for the revised compiler) is tunning again. It looks
like all I have succeeded in doing so far to BT is take a running program
and make it so complicated I can't figure out why it now fails. I suspect
that's the purpose of OOPS, which thus qualifies it
as job security in a down economy. Me, I don't believe in make-work, but
OOPS
(Object-Oriented
Programming) is the technology du
jour, so I'm still trying to make it work. Maybe I'll succeed before I
achieve senility. Maybe my successors will likewise. sigh
2013 June 22. BT started to work and translate John 3:16, and
with a little more effort, now shows the structured output. This could
conceivably exceed the 4K width limit on pixel images, so I added code
to slide a virtual panel around if it got too big. To test it, I thought
I might make some very wide characters, but the glyph editor is broken.
2013 July 12. The glyph editor is finally working, but the translation
engine is now broken in several different places. Sometimes I think God
is more interested in keeping me busy than in seeing this program to completion
and in use. My father spent the last 20 years of his life writing what
he hoped would be a definitive systematic theology textbook. It never saw
the light of day: he went to his grave with it unfinished and unpublished;
I've been wondering now for some time if that's my future too.
2013 July 20. Most things seem to be working (except a few Undo)
but the structured output window gets goofy when it reformats (like if
you change the font) and clicking in some document windows starts to lose
redraws. Nothing catastrophic or unworkable, but ugly. I want it working
reasonably well on the Mac before I start bringing the PC glue up to speed:
if the infrastructure is broken, I don't want to be fighting two battles
at once.
2013 October 9. I think it's working reasonably well on the Mac,
so I'm ready to start bringing the PC glue (and compiler) up to speed.
There may still be bugs in the BT code, but I hope they will appear as
I update the on-line documentation and tutorials. I can exercise or fix
the one while waiting on the other to compile, or a database to rebuild.
2013 October 14. It's working reasonably well on the Mac, and
it compiles to clean C code (on my Mac C compiler with a stubbed version
of <windows.h>) but the PC that sits here mostly silent and
turned off has ceased to function at all -- or maybe it's just the monitor,
which never did work well (it's all cheap Chinese junk). So I'm stuck until
I can fix it. Oh wait, I tested the monitor on the OSX computer, and it
worked fine (other than being dim), so I tried it again on the PC and it
now works fine (other than being dim). Cheap Chinese junk. The VisualStudio
compiler found some problems the Mac C compiler missed (or ignored), fixing
those...
2013 November 5. It now compiles on the PC and even runs for
a while there, but there are still some -- what's the word? "issues" --
problems that need fixing, some code is incomplete, and I seem to have
a memory leak.
2013 November 14. I fixed the memory leak, and DocPrep
ran to completion, building a complete database file on the PC, but BibleTrans
still has problems. I uploaded the source files anyway, because the Turk2C
compiler now works on the PC and compiles itself. I had set this as
a milestone and a fleece, to decide whether I was on the right track. So
I'm still working on it.
2013 November 29. All the known problems are fixed in the current
upload. I didn't test everything, so there may still be unobvious issues.
I guess now I can get started enlarging and simplifying the translation
grammar tables. I probably also should make an effort to minimize "Dangerous"
code (replace unnecessary PEEKs and POKEs with object
access), and maybe move as much C code as possible into T2 (for the same
reason).
2014 February 25. Working through the various things BT is supposed
to do, I fixed numerous bugs and made it slightly easier to build trees
from Greek. I seem to have a particularly nasty bug that kills tree file
import, so I can't make a build with Php trees already in it. No upload
this month. sigh
2014 May 2. All the things BT is supposed to do seem to be working
(on the Mac; the PC still has issues). I finished building Mark 16 and
it seems to translate reasonably. Tree imports seem to be working, but
I found a bunch of problems in EM's trees. Hmm, it looks like I've seen
most of them before, I just didn't remember. Anyway, I'm working through
them now.
2014 May 14. We still have problems with nested
discourse relations, but I uploaded today the complete
source files and a new
runable download.
I will try to get the tree problems fixed in the next few weeks, then maybe
start in on enlarging the tables. If I don't succeed, what is up there
now works.
2014 May 30. I thought it was working, but I had not yet tested
the tree building functions, which were completely broken. New upload now
that I got that fixed.
2014 June 4. I thought it was working, but every time I try something
new, it's broken. Now the Microsoft VisualStudio compiler is misbehaving.
The compiled program works fine inside their debugger, but some operations
crash running standalone. This started a couple months ago with my TAG
compiler, but now it's affecting BT also. I have no idea what the problem
is -- for all I know, it could be a Microsoft time-bomb. Today's upload
omits the step that crashed, but there could be others. sigh
2014 June 11. It seems to be stable (see links for downloads
on May 14 post above), so I'm setting it aside
to develop some marketable skills, in this case programming Android. I
thought of an app *I* would buy a smart phone to be able to use, and it
builds on BibleTrans technology, so it should be easy. Besides, it also
should help if I ever get around to extending BT to include the Old Testament.
2014 November 29. I downloaded a couple independent copies of
the Hebrew Old Testament, and spent far more time than I expected cleaning
up the errors. These are easy to find, because the two versions differ
on the errors -- or else my software chokes on them. But I now have a reasonably
clean Hebrew text with glosses (adapted from the Strongs numbers by comparing
with an English text similarly marked). Now I'm finding a lot of errors
in my supposedly clean Greek NT text. There's nothing like a by-the-rules
computer to find errors in a manually prepared text. So this is taking
longer than I expected (I thought I would be done by now). sigh
2014 December 5. Three months ago my friend Dennis in Dallas
got me into a 3-way phone conversation with a friend of his who has done
some fundraising for non-profits. He said we needed a 3-minute promotional
video. I thought about it and came up with a script
idea. Dennis sent it out to people he thought might be interested,
but nothing happened. This morning, maybe a half-hour before my alarm was
due to go off, I was dreaming of following some movie producer, moving
to Dallas to get his help (for me to make) this video, and I suddenly woke
up with the realization: This isn't my job. Nor is it my job to manage
the BibleTrans project. That's not what God made me good at, and I fail
utterly trying to work with people who might see me in that capacity. I'm
a pretty good programmer, I'm tolerably good at software design, but trying
to relate to other Christians -- other than a few minutes on Sunday morning
in a controlled environment -- only makes them unspeakably angry at me.
We really need somebody with a vision for computer-assisted Bible translation
who can protect the rest of the team from me. I don't know how to
find that person, but we really need a team of people to encode the database
and train the users, and we need somebody to head up that team with a different
personality type than mine, somebody with good anger management skills
when dealing with me, and good administrative skills when dealing with
the rest of the team, and who can transition the technical side of this
off to younger people who can carry the ball after I stop being compos
mentis. Both my parents lost their marbles in their early 80s and died
before 85. If that's any predictor, I will become useless in ten years
or less. With a big enough team working on it, maybe we can finish all
the translations of the world and Jesus will come before I turn into a
pumpkin, but it could take longer: BibleTrans is already 19 years old.
2015 January 28. My friend Dennis is a member of a mega-church
in the Dallas area. He connected there this week with a young video professional
willing to make the promo video (see Dec 5) at a
price we can afford. It turns out Dennis also has connections that might
lead to funding. Whatever God wants to do with this, that's what's going
to happen. I just need to be ready to roll when it does.
2015 February 21. Today I signed papers to move to Texas. Dallas
seems to be where things are likely to happen, and I need to be there when
it does. Maybe nothing will happen, maybe it will (God only knows), but
the State of Misery is certainly a dead end, and I'm out of here (in May).
2015 June 25. Arrived in Texas with my stuff. I previously thought
the State of Misery was bad, Taxes is worse in spades.
2015 September 24. Texas is big, and what they get wrong, they
get wrong big. One of the leaders in my friend's church has an anger management
problem, and he planned (and executed) his revenge by destroying my friendship
with Dennis. Maybe he will recover, maybe not, but it leaves me high and
dry. Dunno where God wants to go from here.
2016 March 8. My friend is gone, having chosen "freedom and happiness"
(his words) over BibleTrans. I don't think he will find it where he's looking,
but that's his problem, not mine. My problem is that I still need
to find somebody with people skills who wants to take BibleTrans to the
next level. I'm obviously not it.
2016 August 22. It's not happening here in Texas, and I have
family in Oregon -- who wants to grow old in Oregon? That's the first place
in the USA they imported the Dutch right to kill sick people against their
will, but they made that choice, not I -- and I'm getting to the age I
need somebody nearby who cares enough to drive me to the hospital if necessary,
so I'm going to Oregon. God can do anything He wants, and if He wants to
revive BibleTrans, I will jump on it like there's no tomorrow. Until then,
I need to find something else to do.
Next (most recent) posting at top